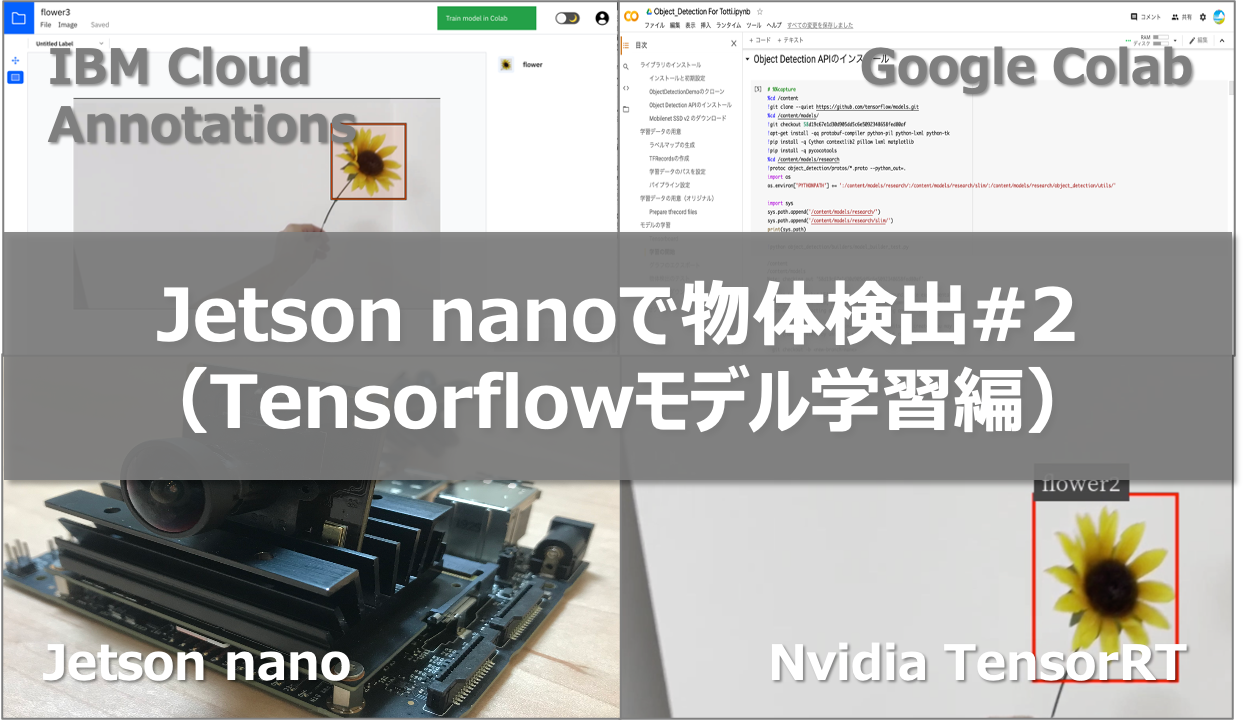
はじめに
オリジナルモデルを使った物体検出をJetson nanoで行うべく、以下を実現しようとしています。
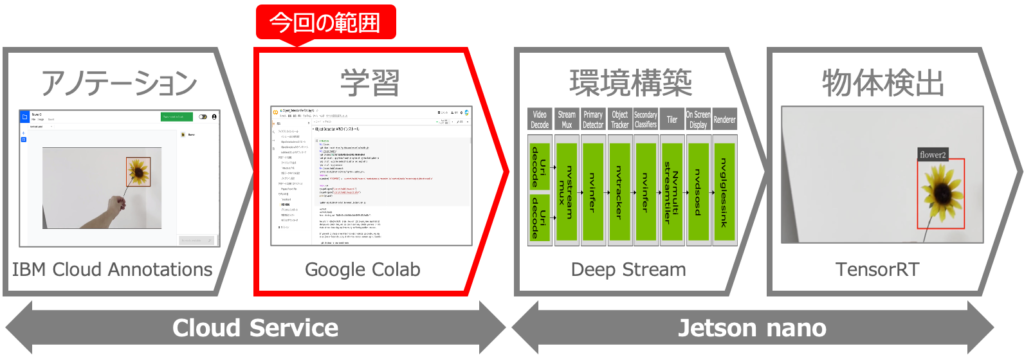
これを実現するために5回に分けて記事を記載予定で、今回は2つ目の記事です。
第1回:IBM Cloud Annotationsを用いたアノテーション
第2回:Google Colabを用いたモデルの学習 ←この記事
第3回:Jetson nanoの環境構築
第4回:DeepStreamアプリを使いこなす
第5回:学習モデルの変換と物体検出
第2回:Google Colabを用いたモデルの学習
前回は、IBM Cloud Annotationsを使って学習データを作成(アノテーション)することをやりました。今回は、Google Colabを用いて、Tensorflowのモデルを学習させていきます。この学習処理には膨大な浮動小数点演算が必要なのですが、Google Colabを使うことで、無料のGPUを使って高速に実行できます‼️
Google Colab環境の準備
まずは、Google Colabの環境を整えていきます。
①Jupiter notebookのダウンロード
初めに、私がカスタマイズしたJupiter notebookをダウンロードして下さい。このnotebookは、基本的には公式のobject-detection.ipynbの通りですが、以下の7点変更を加えています。
①エラーが出て進まない部分の解決
②SSD mobile net v2 cocoの利用
③Google Driveのマウント
④Google Driveに格納されたテスト画像を使ったテスト
⑤学習済モデルのダウンロード機能
⑥ステップ事に確認しながら進める確認ステップの追加
⑦日本語による記載
特に、公式のobject-detection.ipynbで利用している「ssd_mobilenet_v1_quantized」のモデルは、後にpbファイルをTensorRT用のuffファイルに変換する時にエラーが出るので「SSD mobile net v2 coco」を利用することがポイントです。
エラーを解消しながらこのnotebookを作成するのに3週間かかりました💦💦
②Google Driveの準備
次に、お使いのGoogleアカウントでGoogle Driveにアクセスし、左上の「新規」のボタンをクリックします。
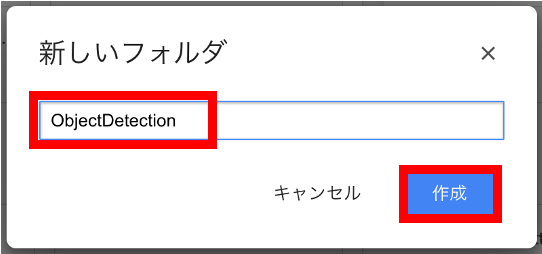
③フォルダの作成
出てきたメニューから「フォルダ」を選択し、「ObjectDetection」とフォルダ名を入力し「作成」ボタンをクリックします。※違う名前でも大丈夫ですが、nodebook上のパスを書き換える必要があります。
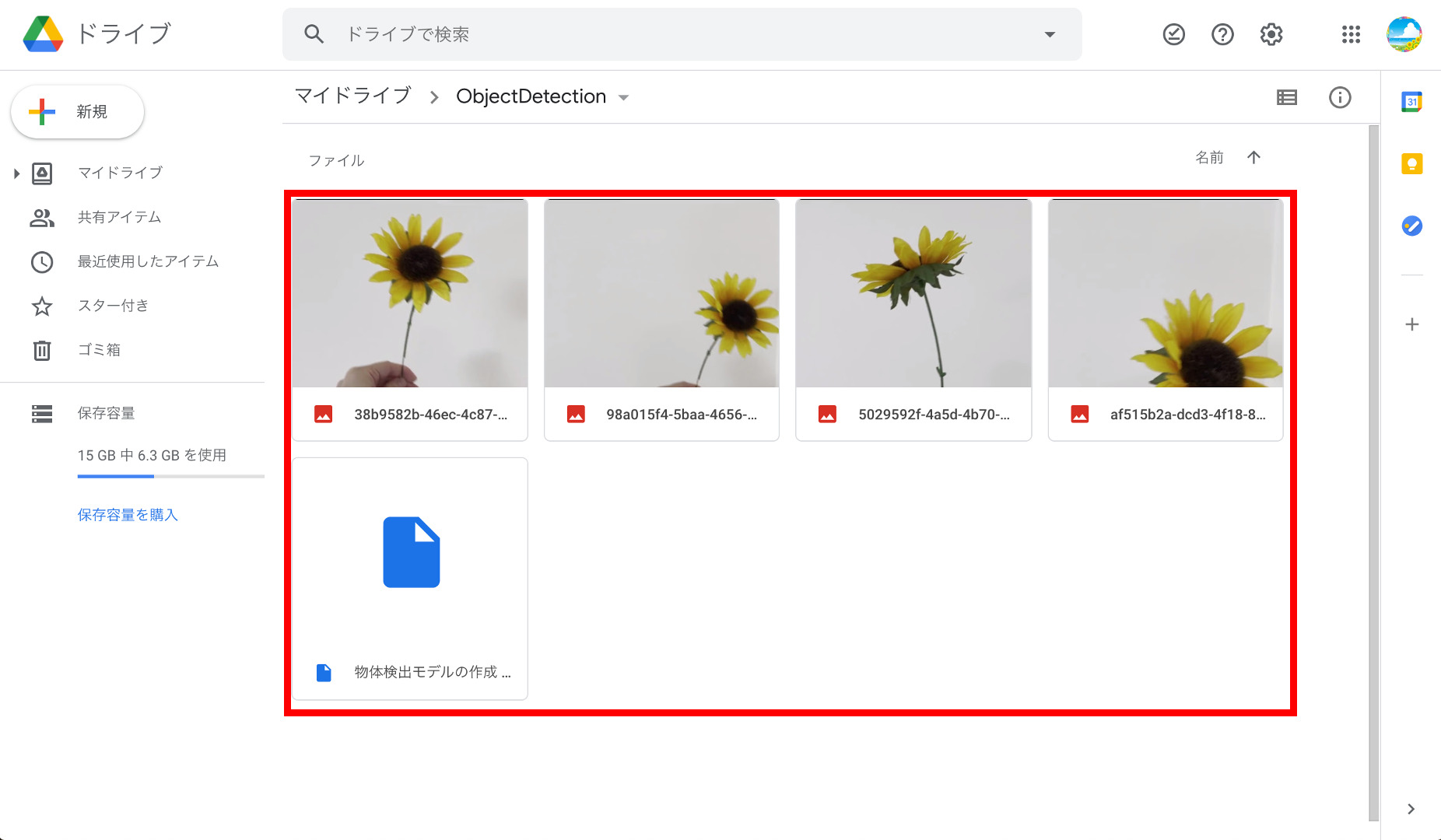
④ファイルのアップロード
作成した「ObjetcDetection」フォルダを開き、上でダウンロードしたZIPファイルの中にある「物体検出モデルの作成 .ipynb」と、第1回目でテスト用に撮影したjpg画像をアップロードします。
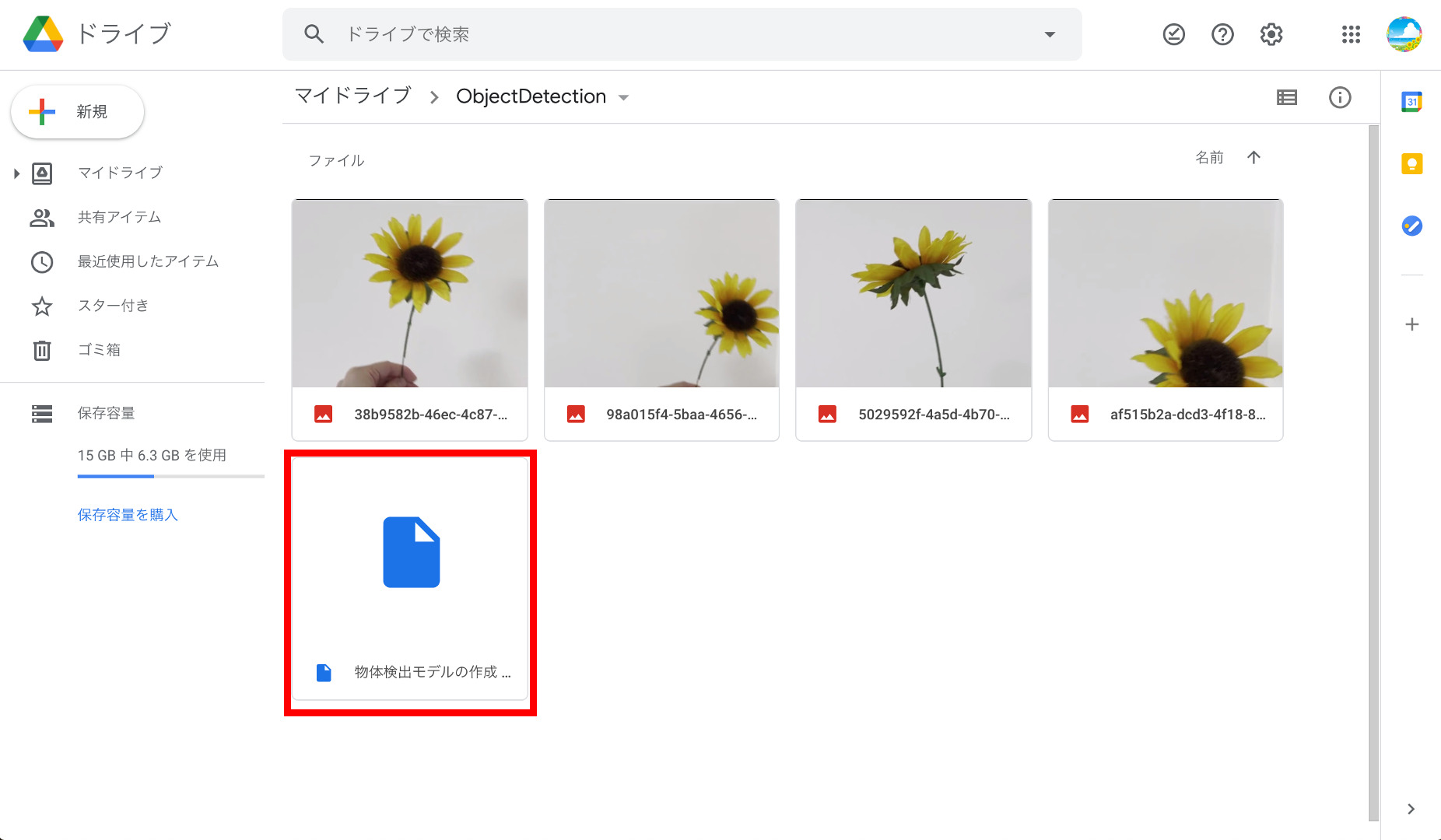
⑤Google Colabを開く
アップロードした「物体検出モデルの作成 .ipynb」をダブルクリックして開きます。
notebookを開くと、以下のようなGoogle Colabの画面が表示されます。
⑥GPUの確認
画面左上の「編集」から「ノートブックの設定」を選択します。
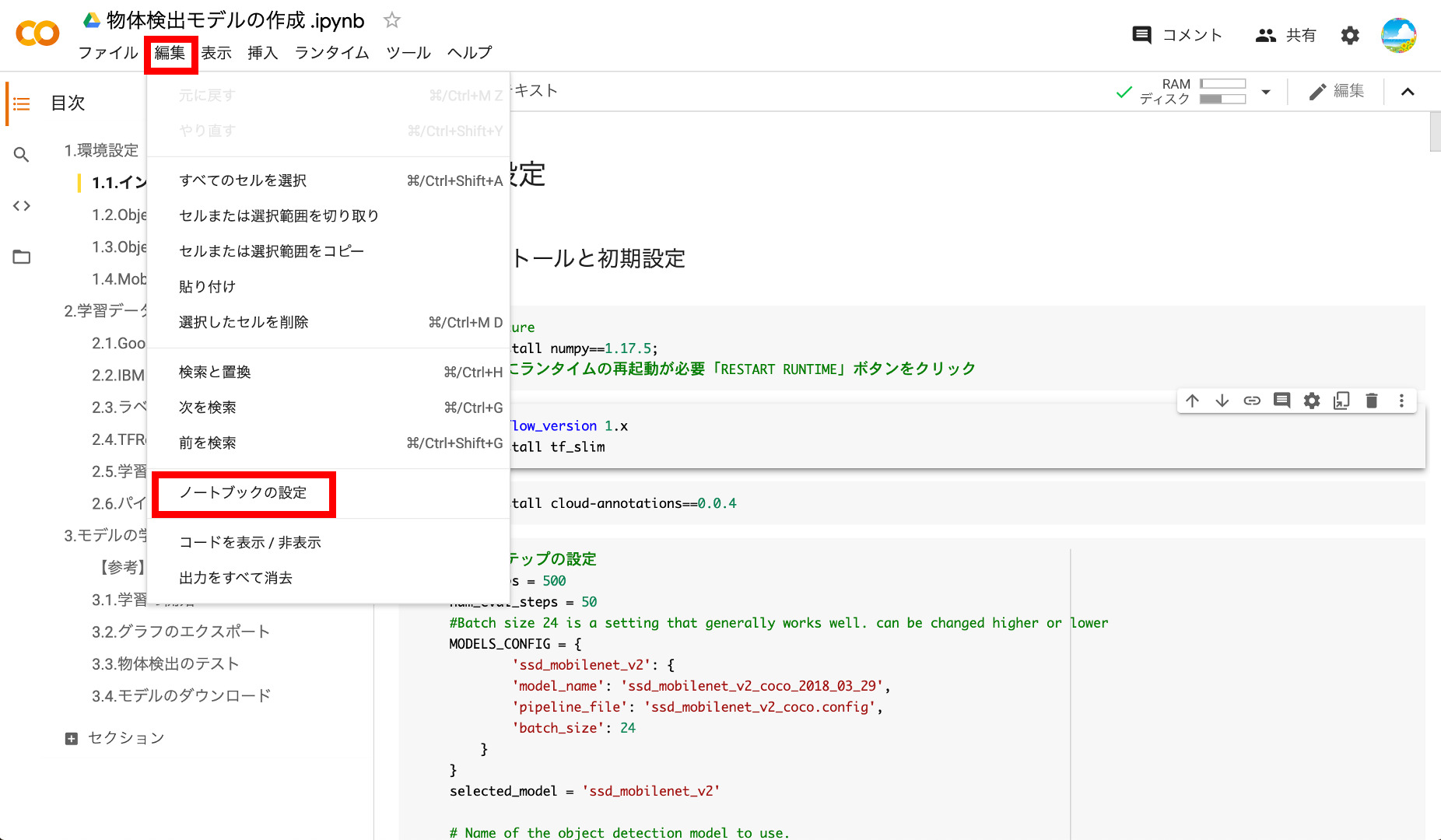
この画面で、ハードウェアアクセラレータが「GPU」になっている事を確認し「保存」をクリックします。
以上で、Google Colab環境の準備は完了です。
サーバの環境設定
ここからはnodebookに記載の「1.環境設定」の内容に従って、上から順にコードを実行していきます。Google Colabのサーバ環境は、必要最低限のパッケージしかインストールされていない状態ですので、Tensorflowのモデル学習に必要なモジュールをインストールしていきます。
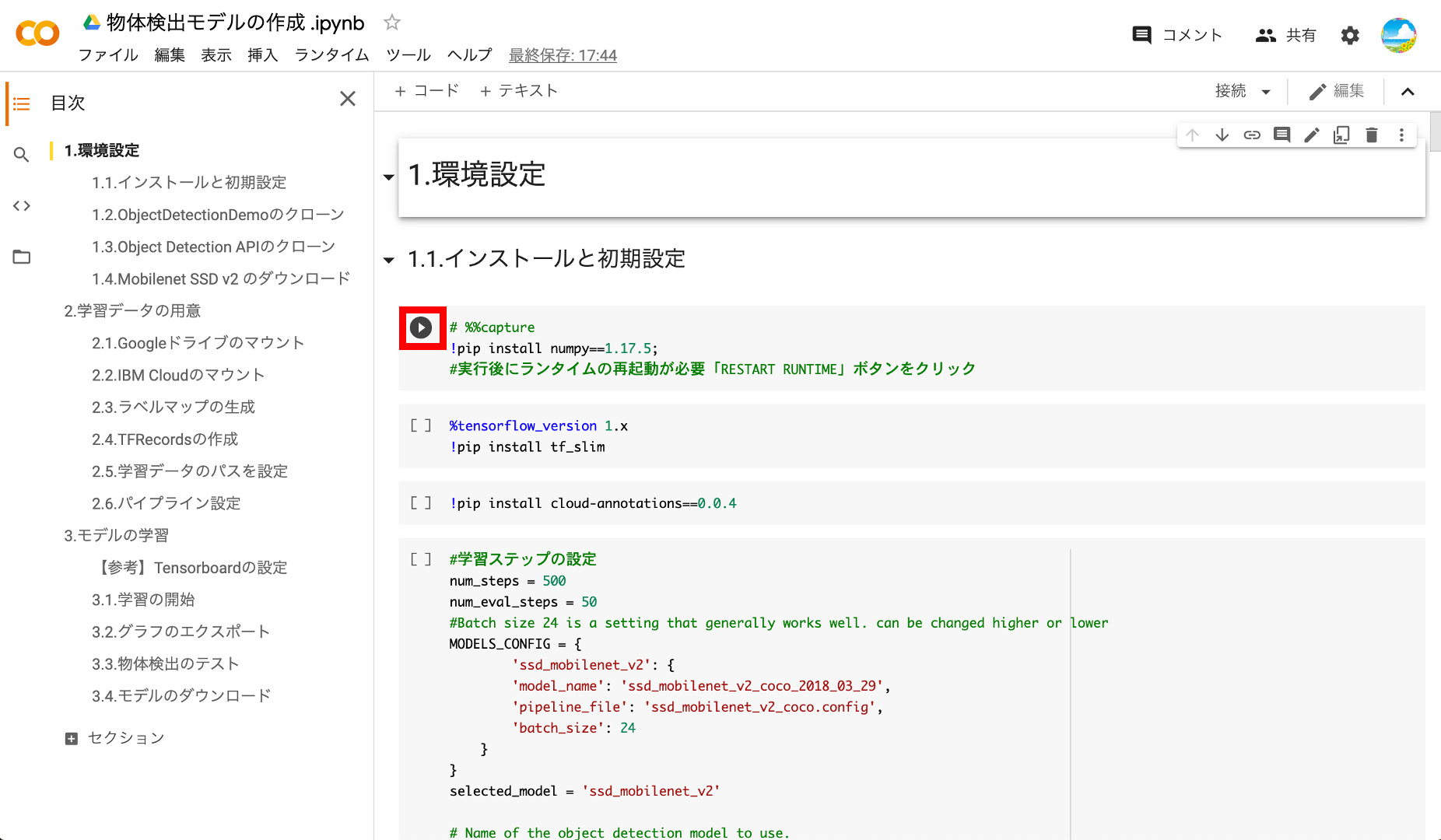
①numpyのインストール
まずは、numpyをインストールします。具体的には、コードの左側にある再生ボタンをクリックします。
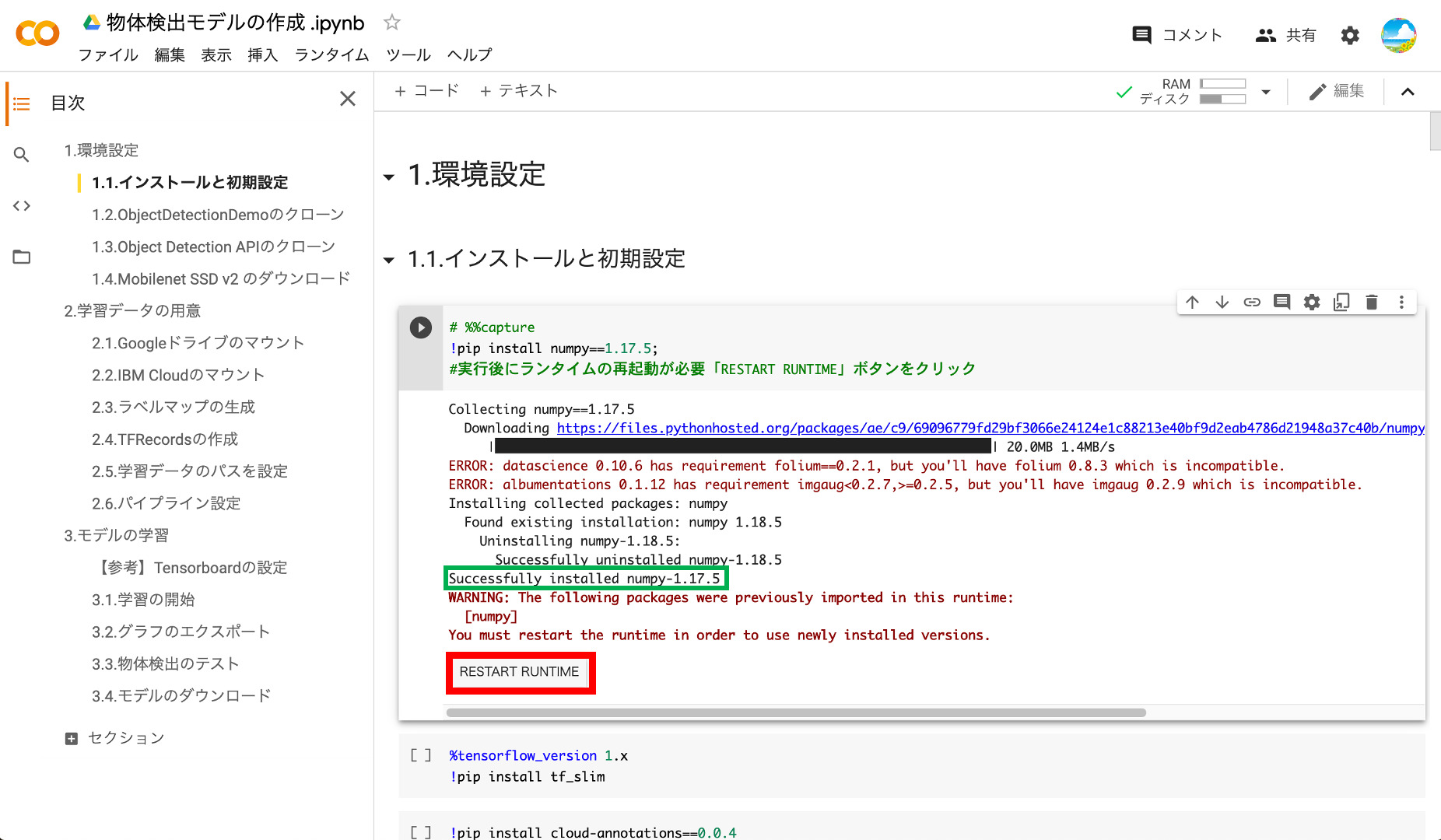
インストールが完了すると「Successfully installed numpy・・・」と表示されます。numpyのインストール後にはインスタンスの再起動が必要との事で「RESTART RUNTIME」のボタンをクリックします。
②tf_slimのインストール
次に、tf_slimをインストールします。「Successfully installed tf-slim・・・」と表示されればOKです。
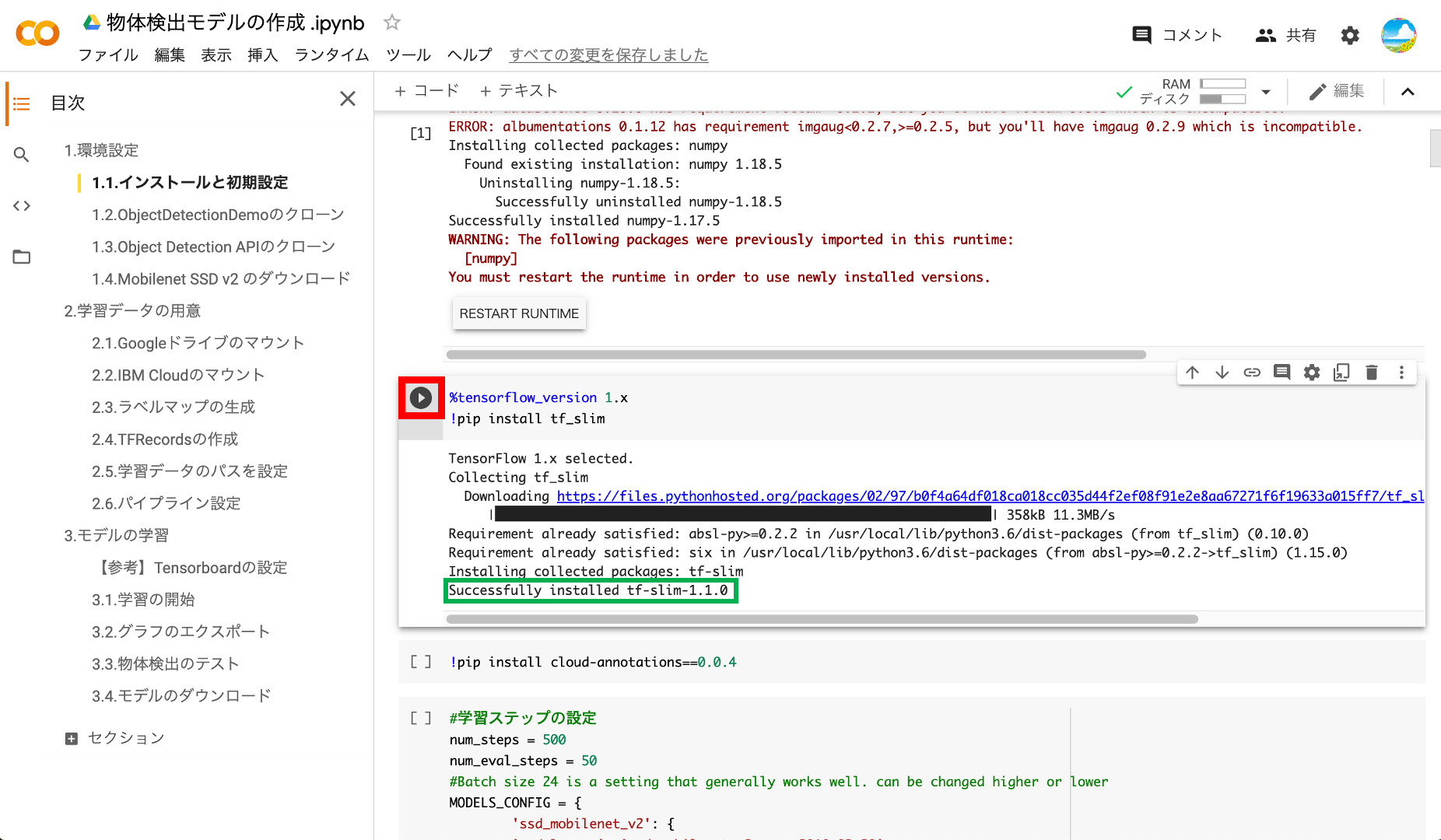
③cloud-annotationsのインストール
IBM Cloud Annotationと接続するためのcloud-annotationsをインストールします。「Successfully installed cloud-annotations・・・」と表示されればOKです。
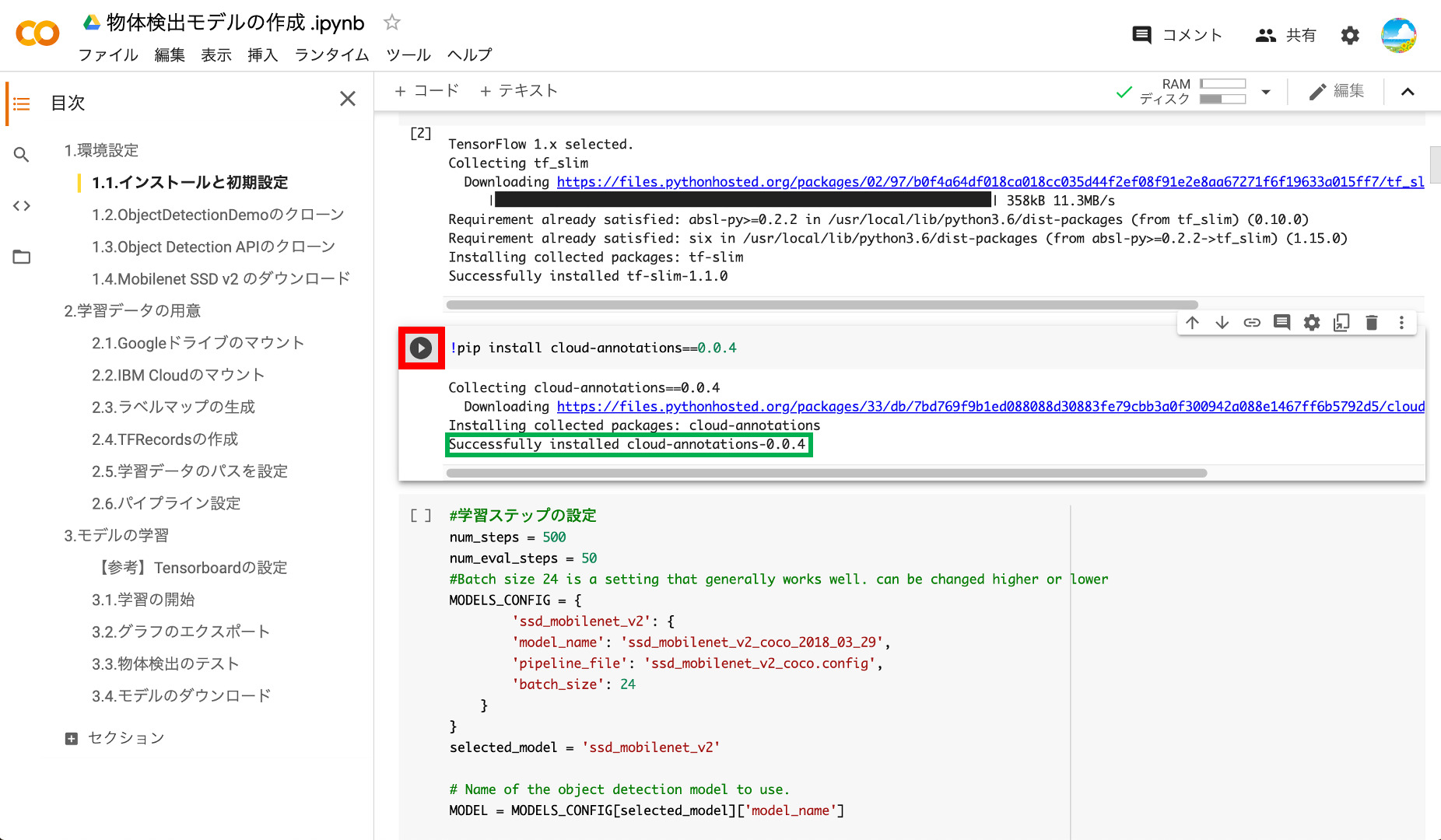
④学習ステップ数の設定
学習のステップ数を変更したい場合には、ここで「num_steps」の値を変更します。初期設定は500にしていますが、物体検出の精度を出すためには最低でも5000ぐらいにしたほうが良いです。設定ができたら再生ボタンを押して実行します。特に結果は表示されません。
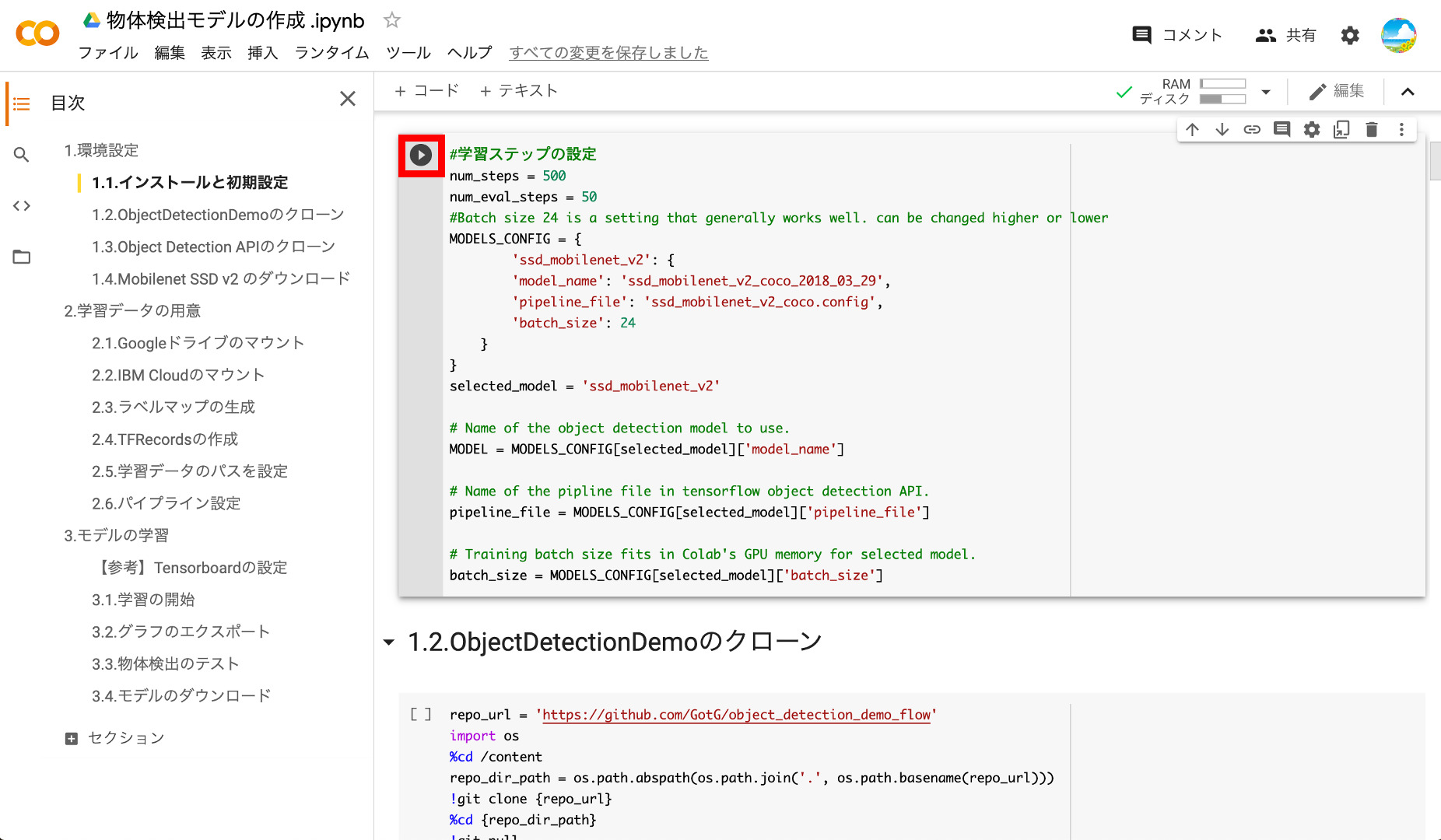
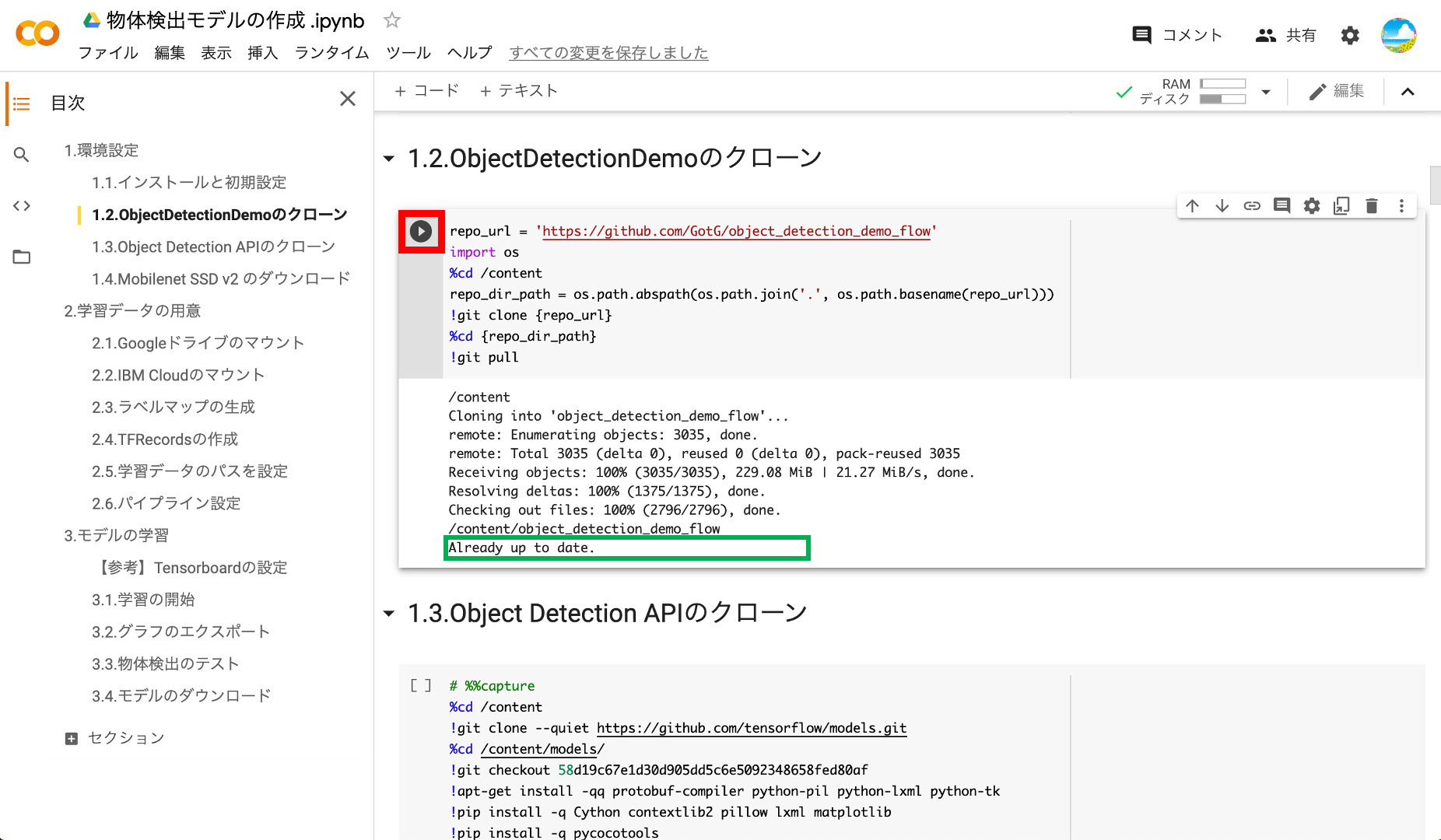
⑤ObjectDetectionDemoのクローン
SSD Mobilenet v2 を使った学習を行うために「object_detection_demo_flow」をクローンします。「Already up to date」と表示されればOKです。
⑥Object Detection APIのクローン
次に、TensorflowのObject Detection APIをクローンし、必要な関連モジュールをインストールします。
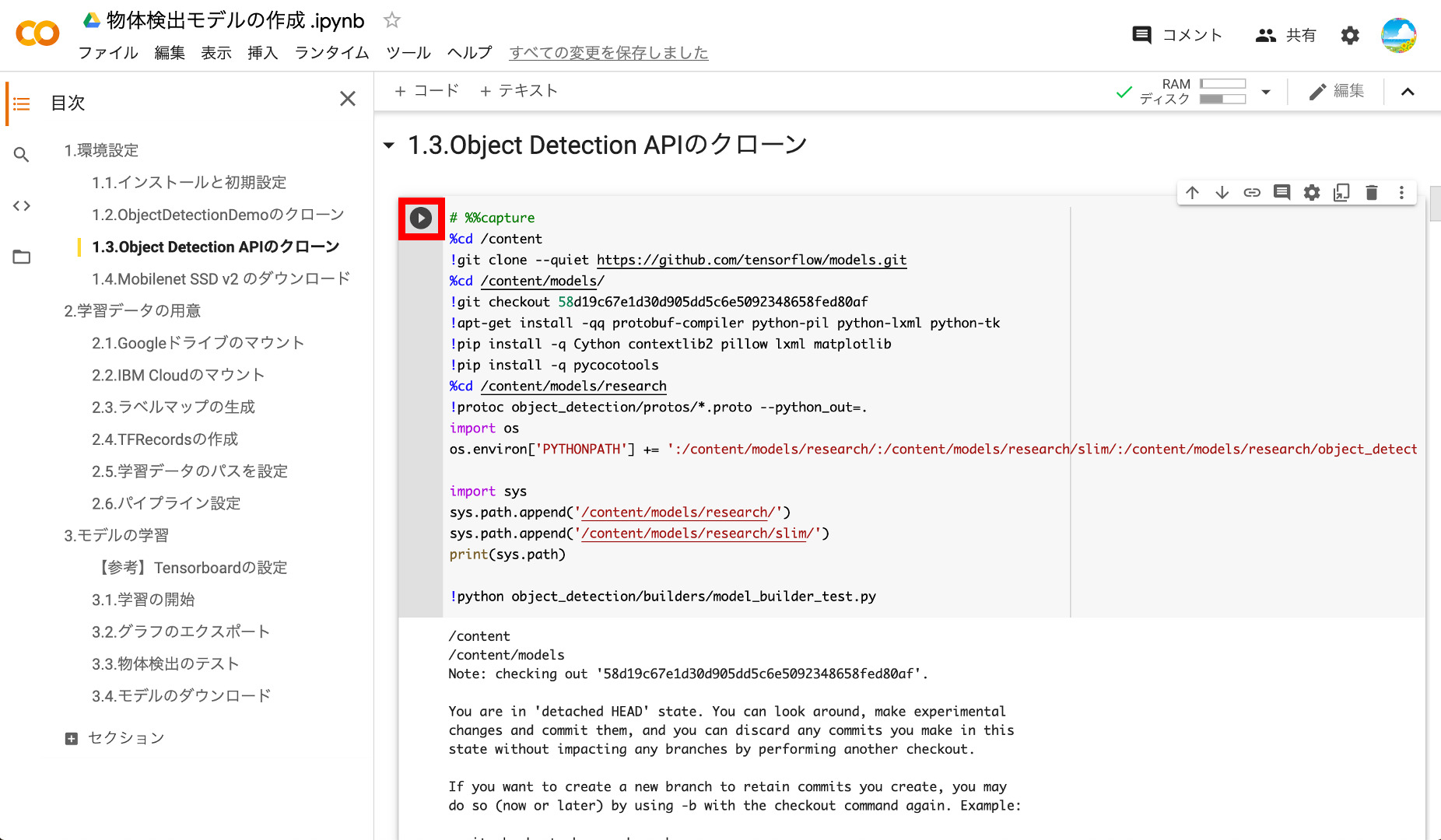
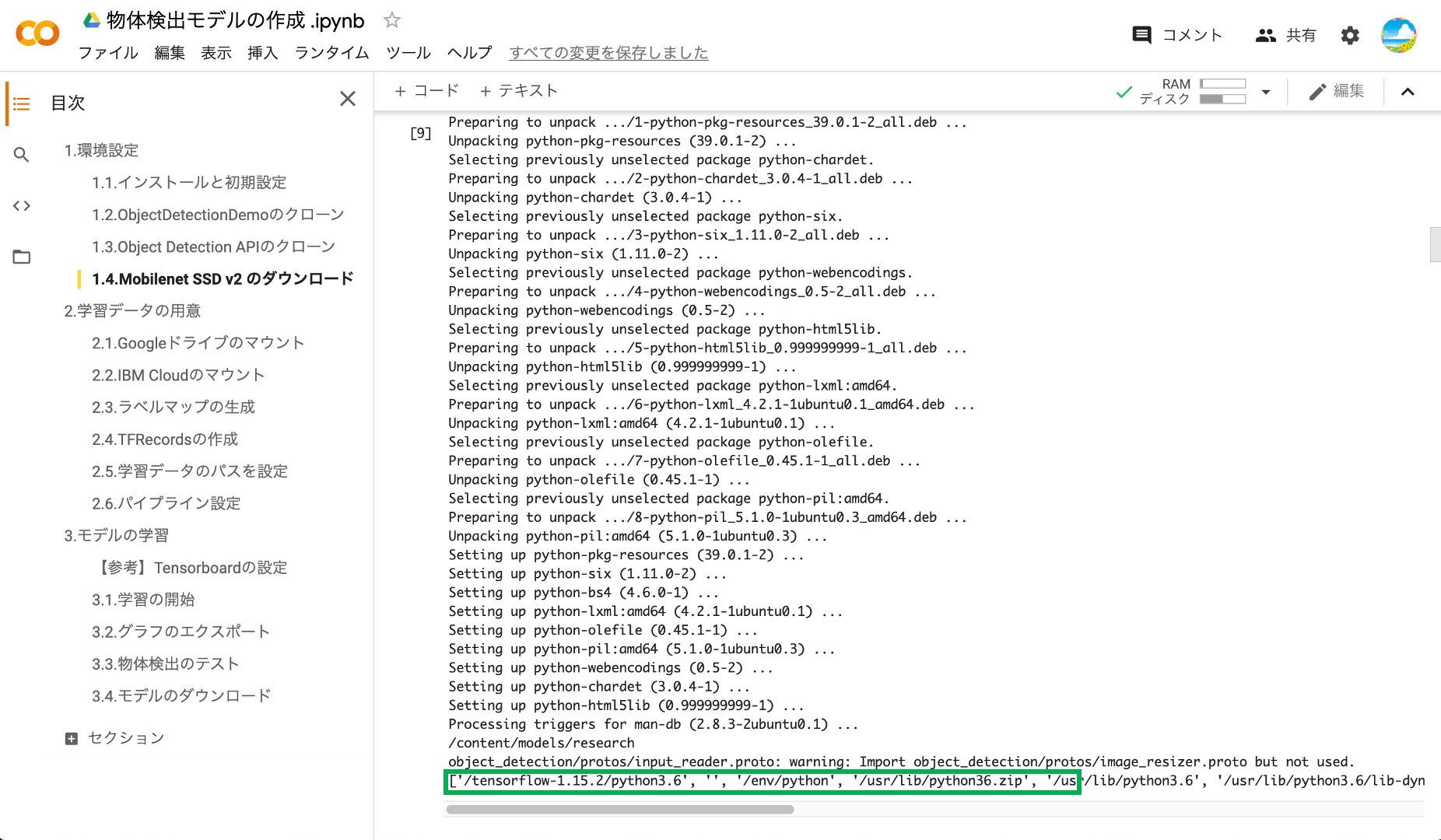
インストールが完了すると、環境テスト用の「model_builer_test.py」が実行され、必要なモジュールがインストールされているかテストされます。以下のように、エラーが出ていなければOKです。
⑦Mobilenet SSD v2のダウンロード
次に、学習モデルのベースとなるSSD Mobilenet v2をダウンロードします。
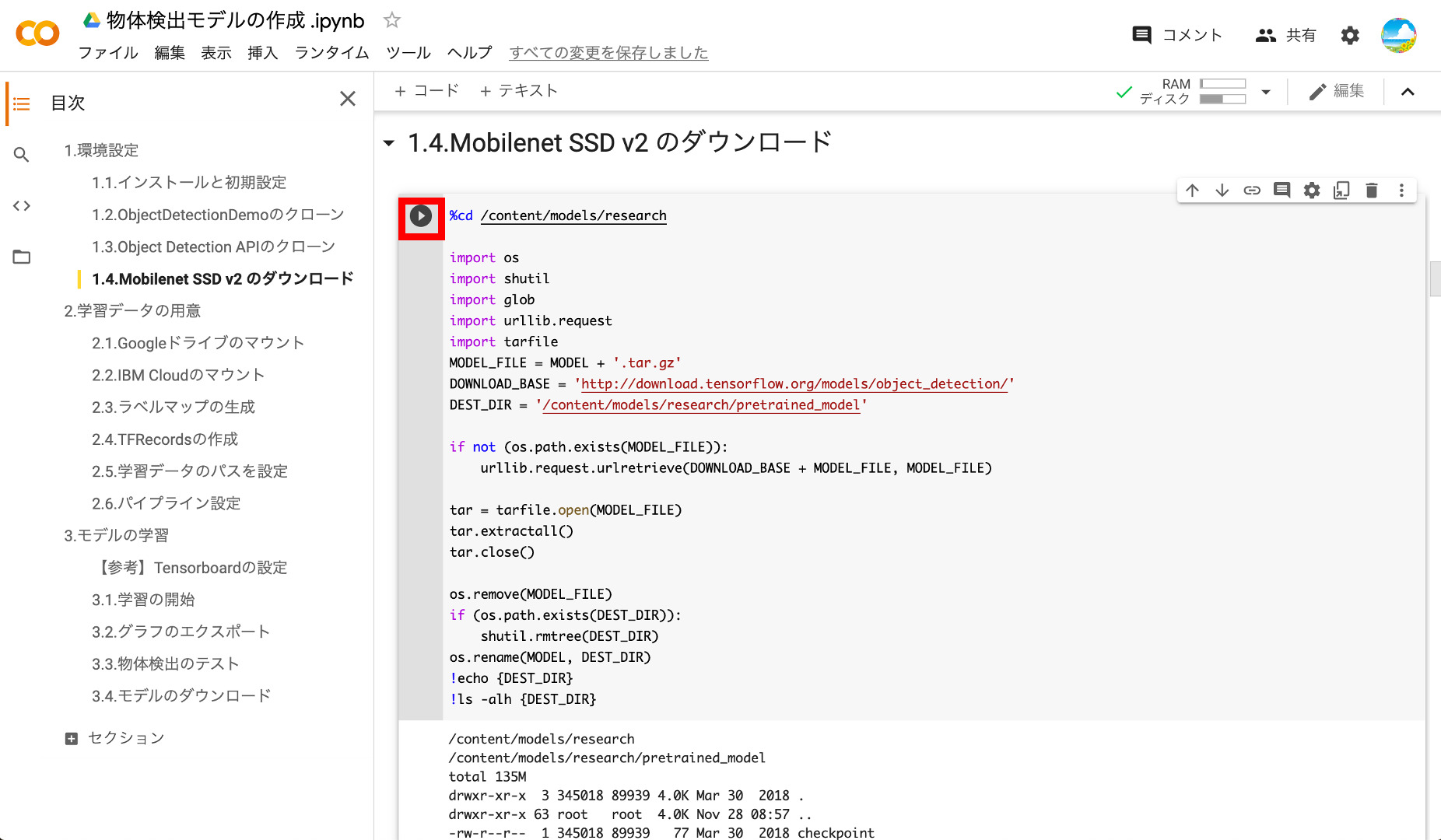
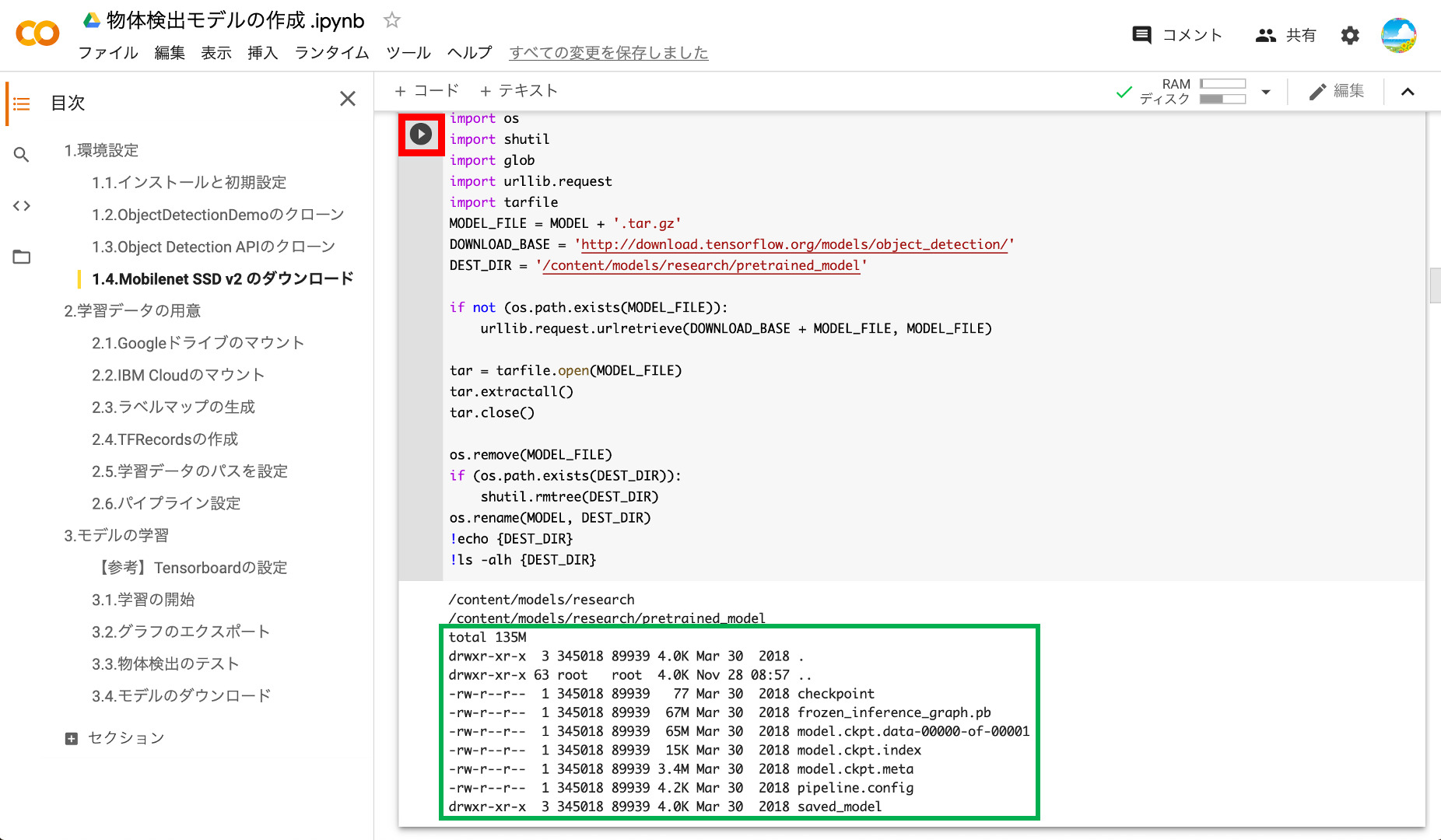
以下のように「frozen_inference_graph.pb」などのファイルが見えていればOKです。
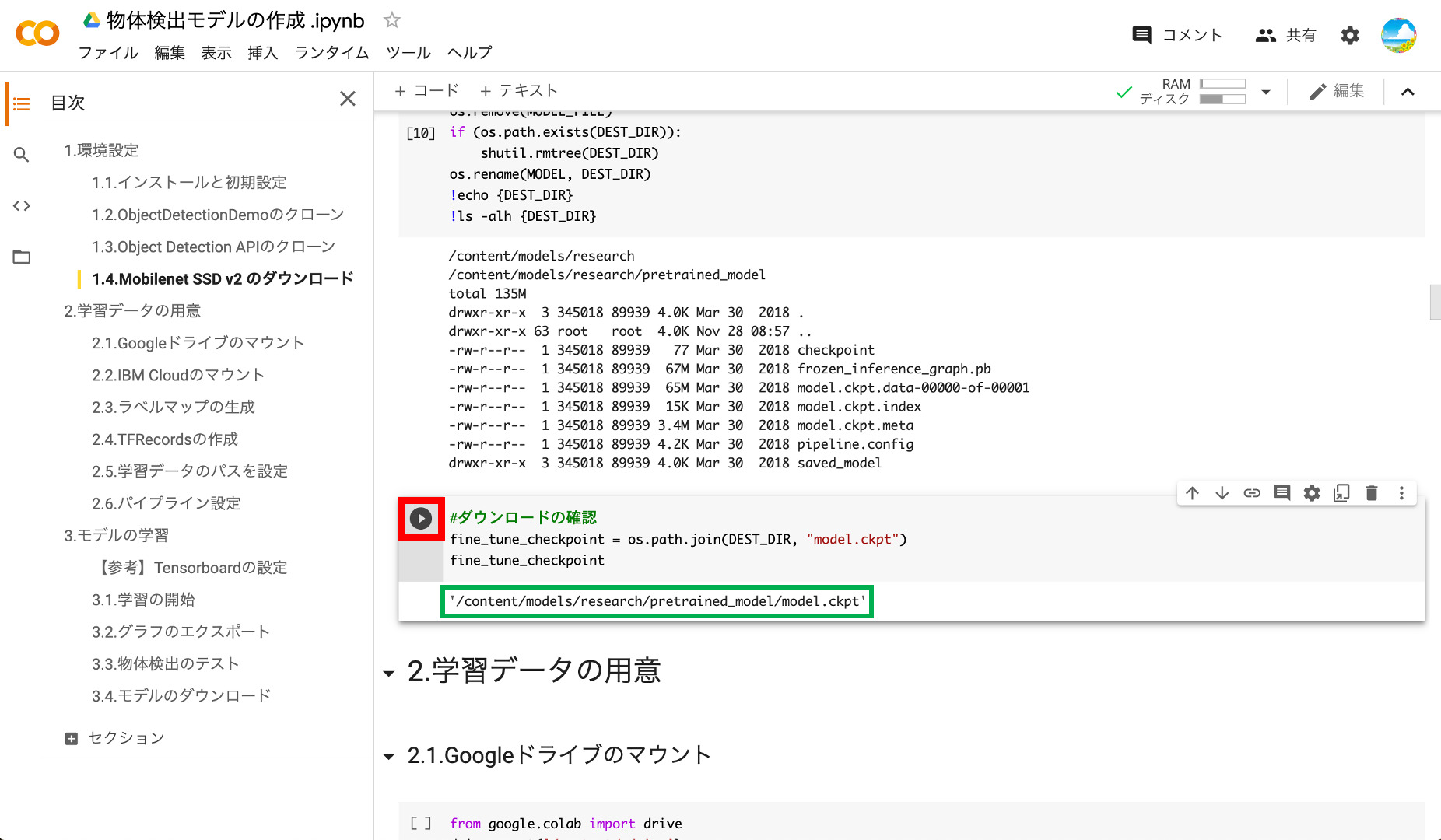
⑧チェックポイントの設定
最後にダウンロードしたSSD Mobilenet v2に含まれるcheckpointを変数に設定します。以下のように「model.ckpt」のパスが表示されればOKです。
以上で、サーバの環境設定は完了です。
学習データの用意
ここからは、第1回でIBM Cloud Annotationsを使って作成した学習データをTensorflowが扱えるTFRecord形式のファイルに変換し、学習データを用意します。基本的には「2.学習データの用意」の上からコードを実行していくだけです。
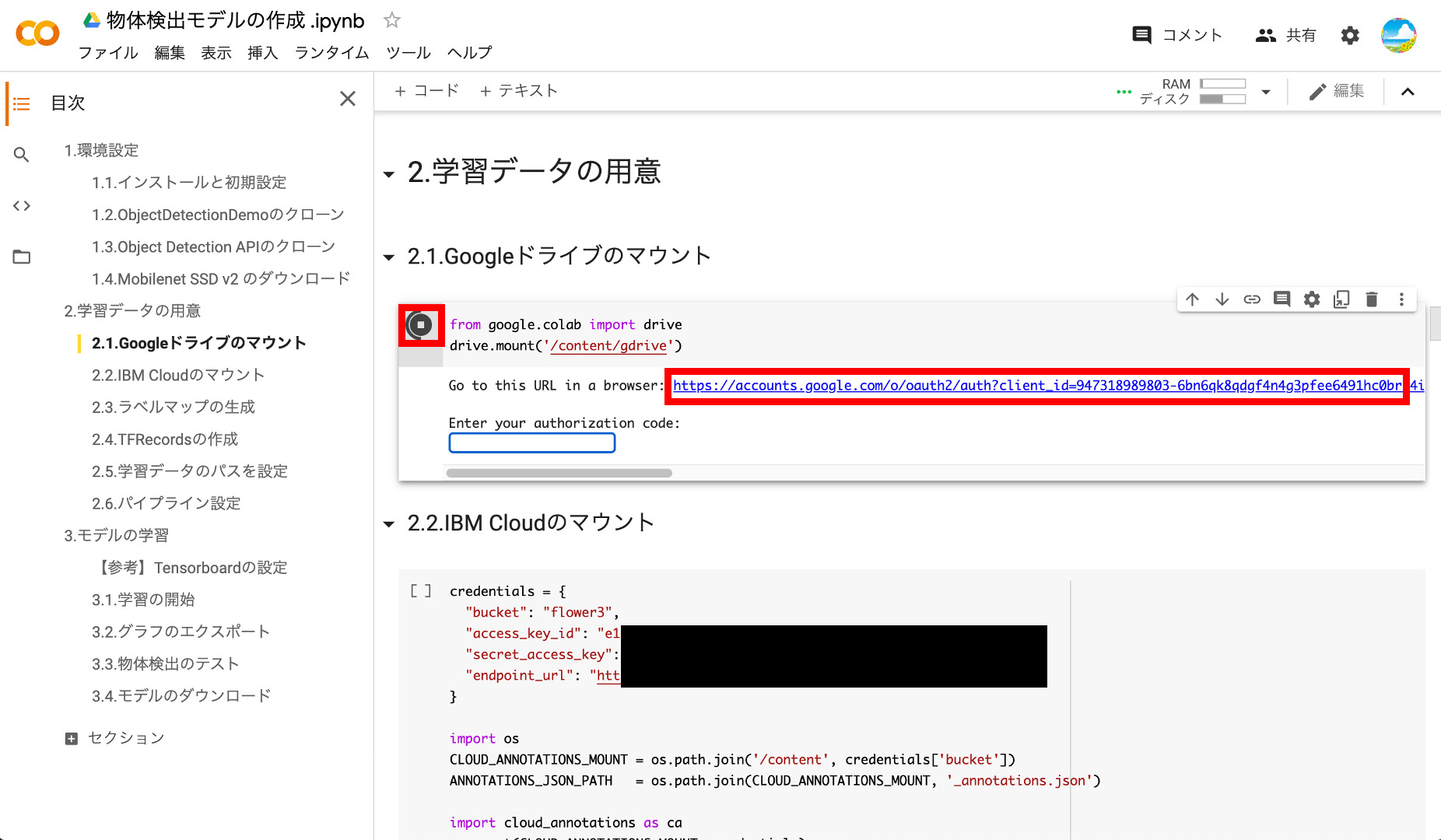
①Googleドライブのマウント
後で利用するので、自分のGoogleDriveをマウントします。再生ボタンを押してコードを実行すると、以下のようにURLが表示されるので、これをクリックして開きます。
すると、Googleアカウントの選択画面が表示されるので、Googleアカウントを選択します。
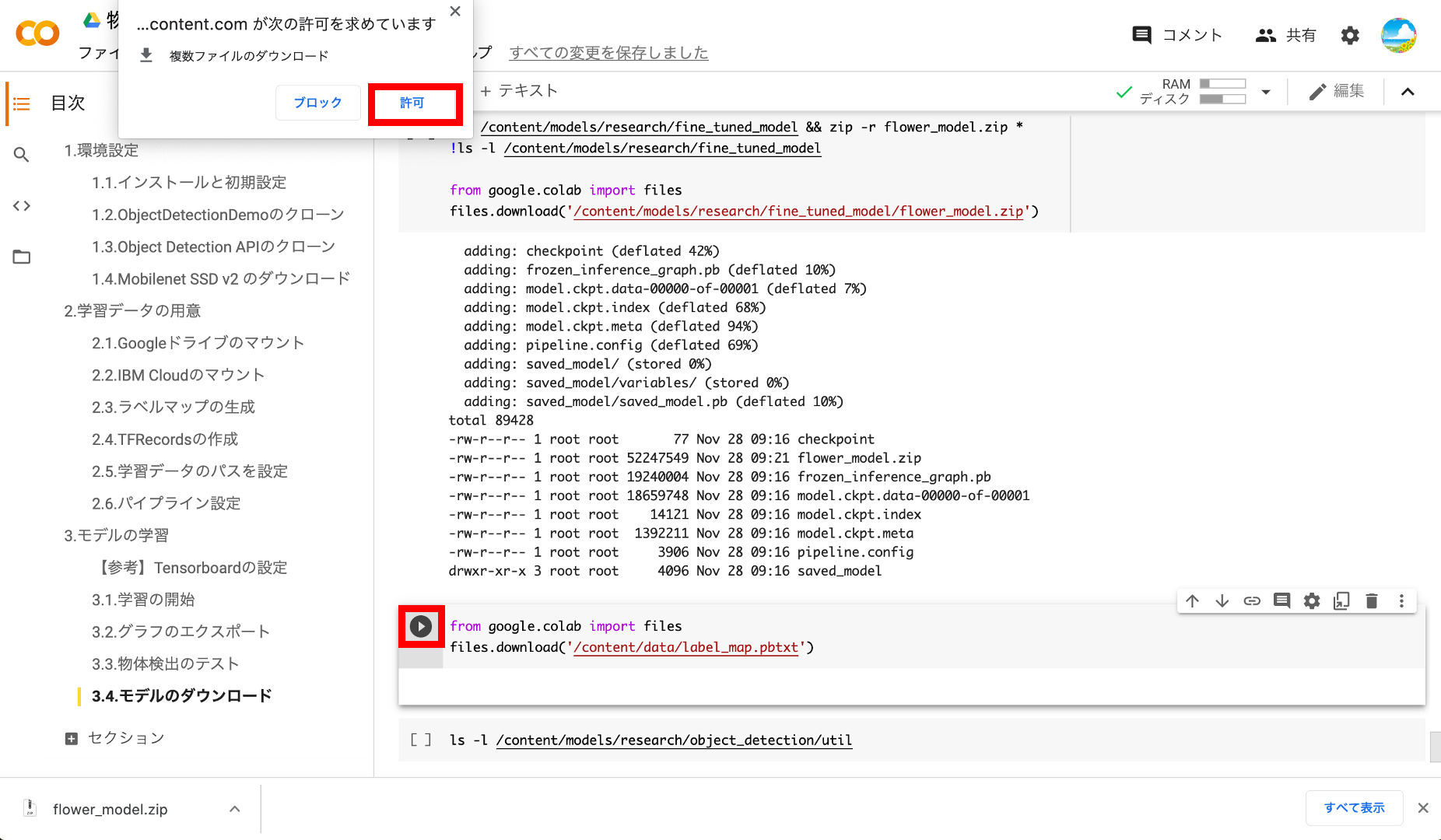
次に、Google Drive File Systemよりアクセスの許可を求められるので「許可」ボタンをクリックします。
許可すると、画面にコードが表示されるので「コピー」ボタンを押して、クリップボードにコピーします。

コピーしたら、Google Colabのタブに戻り、コピーしたコードを赤枠の中にペーストしてエンターを押します。
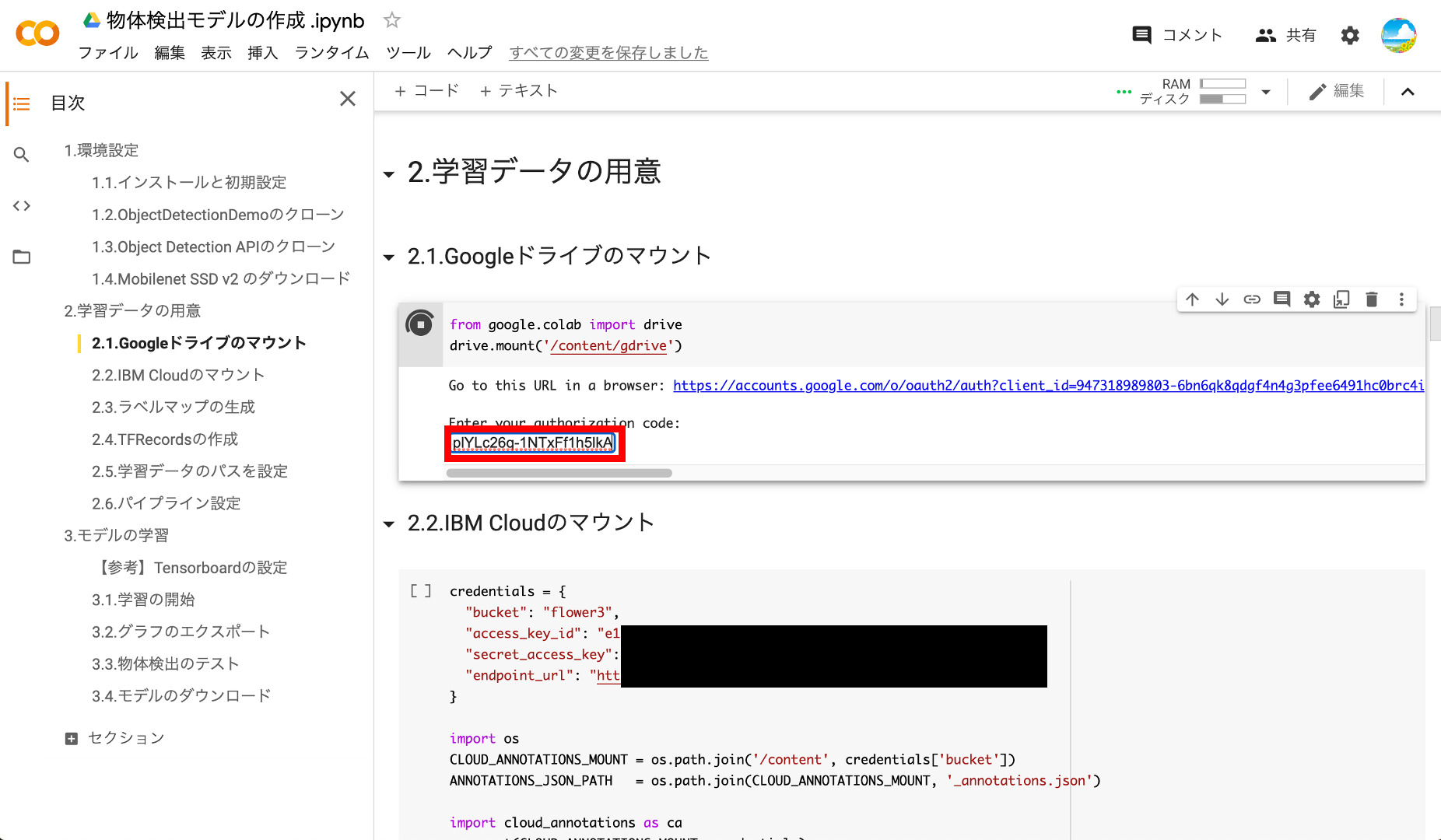
コードが認証されると「Mounted at /content/gdrive」と表示され、Google Colab上のサーバ上に自分のGoogle Driveがマウントされます。
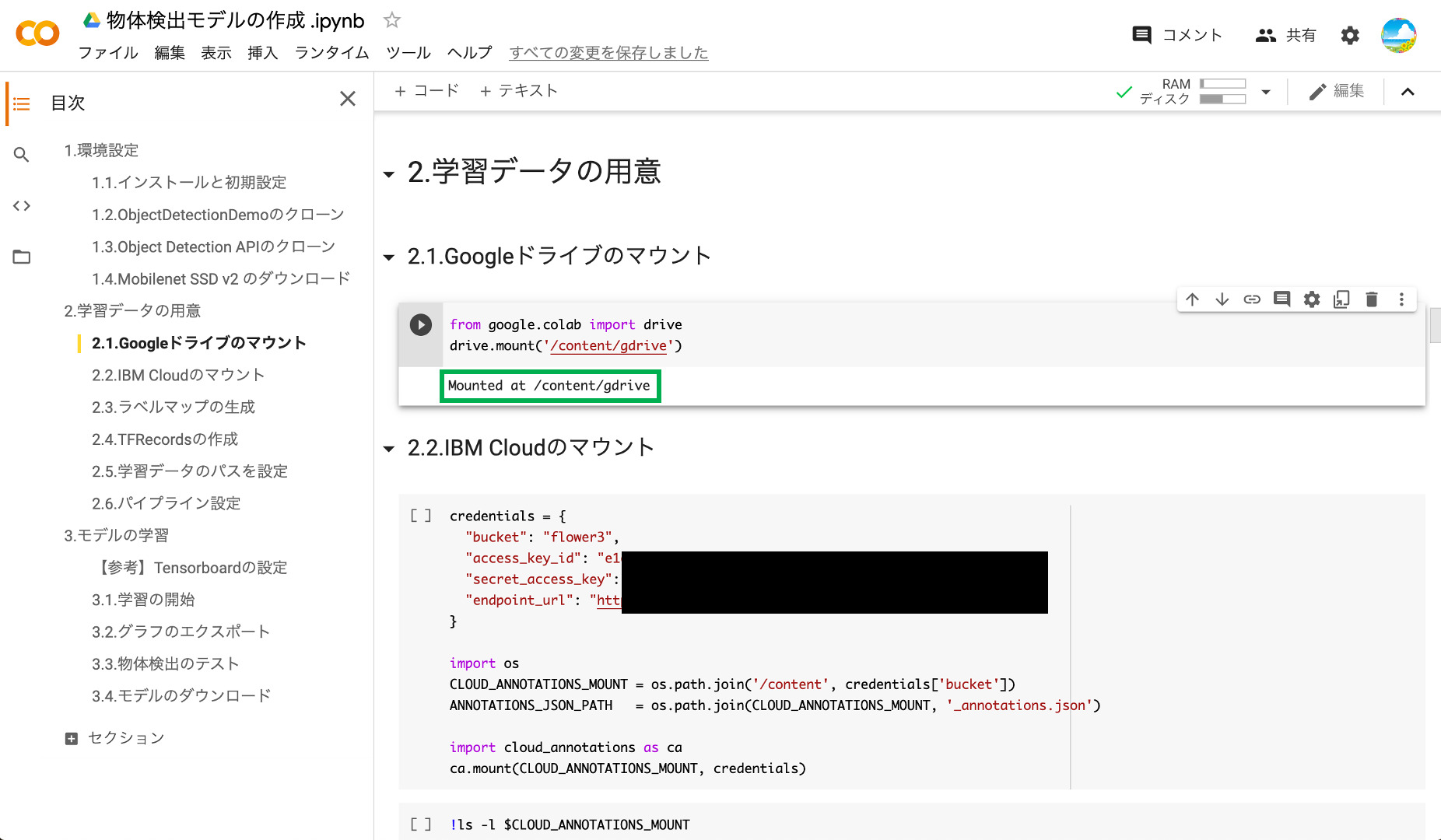
②IBM Cloudのマウント
前回アノテーションしたデータにアクセスするために、IBM Cloudのストレージをマウントします。再生ボタンを押す前に「credentials」の部分を前回メモしたものに書き換えます。
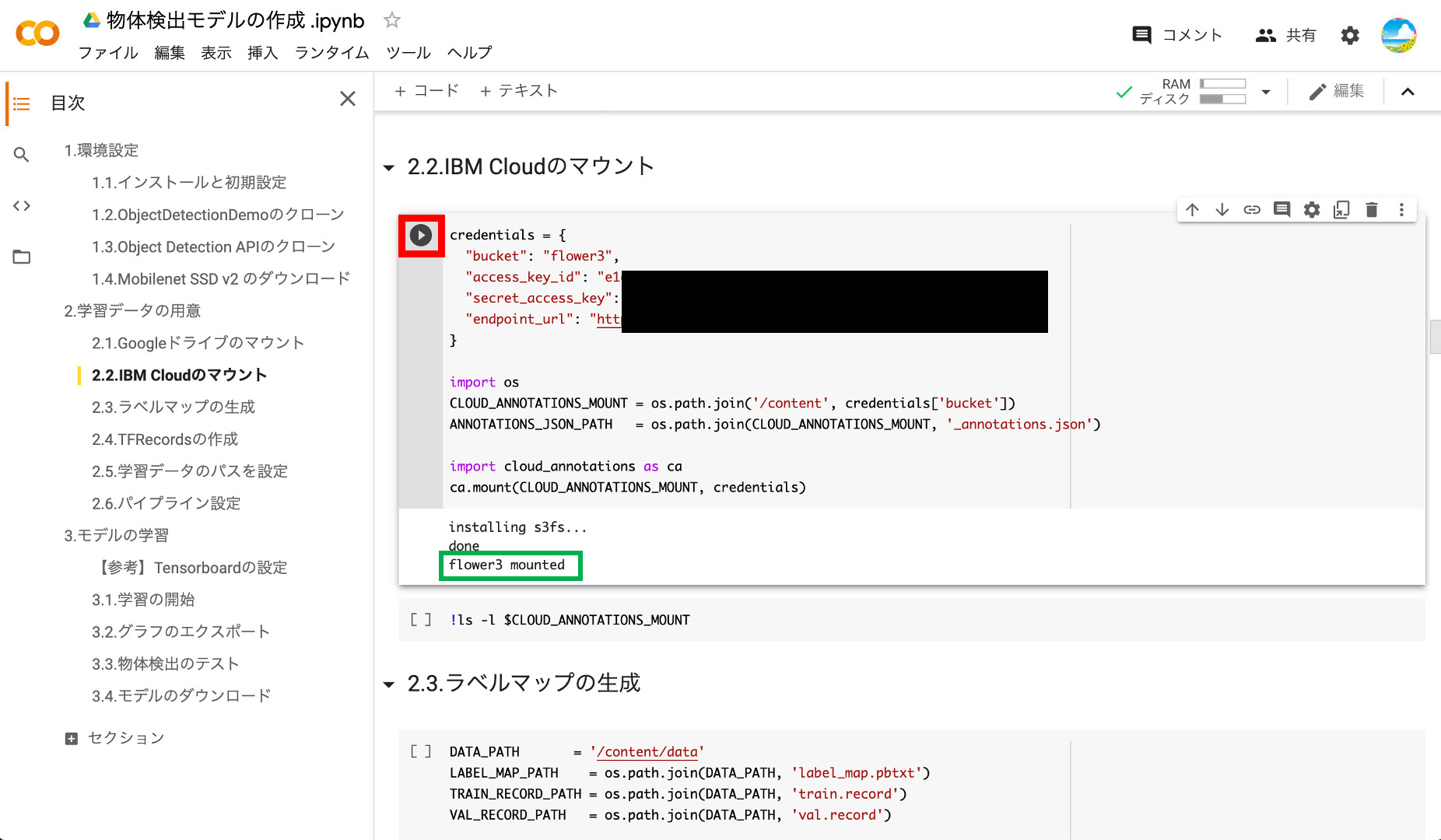
書き換えたら再生ボタンを押してコードを実行します。「○○ mounted」と表示されたらマウント完了です。
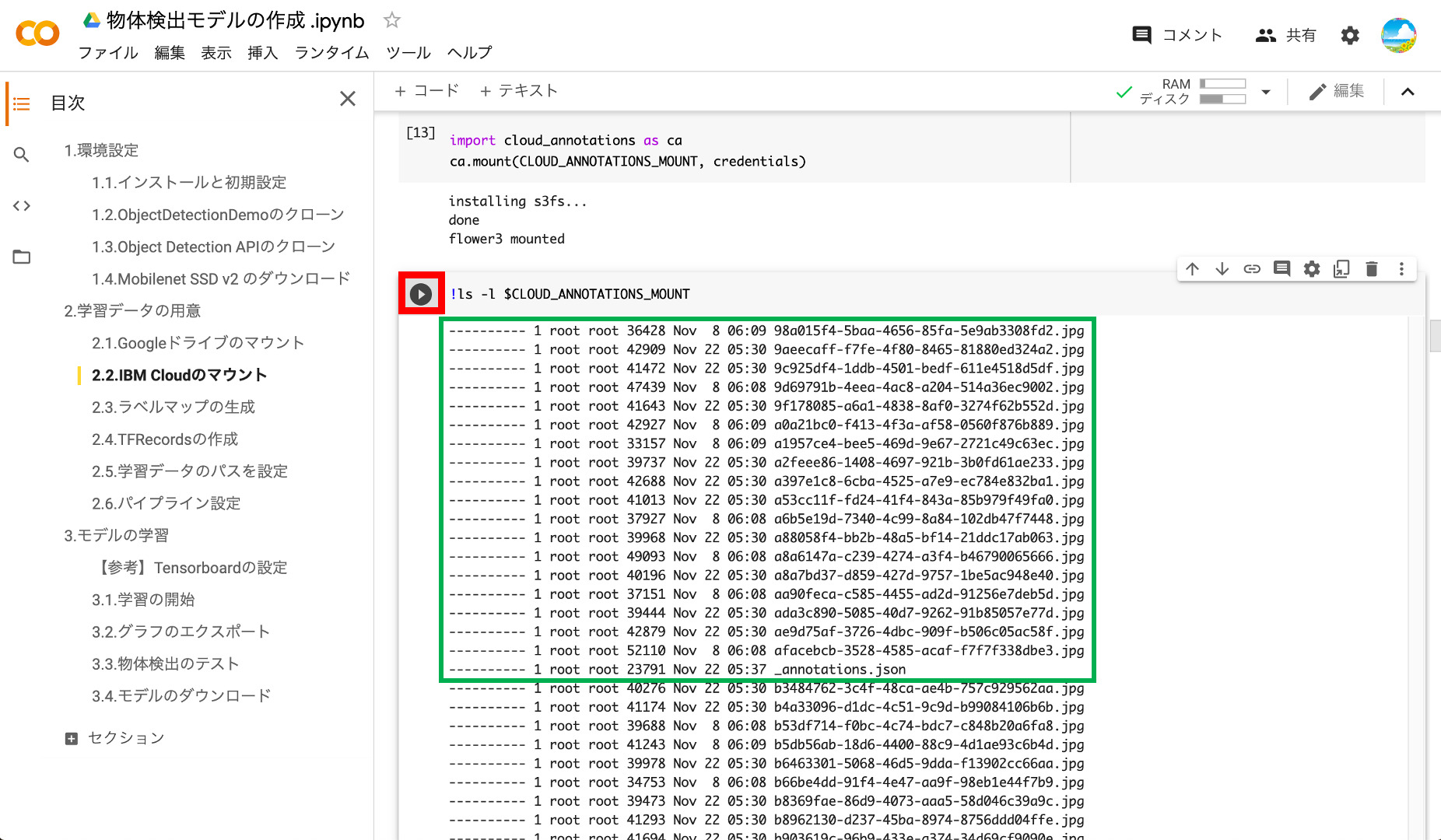
③アノテーションデータの確認
次のブロックの再生ボタンを押すと、前回アノテーションした画像ファイルやjsonファイルが表示されます。これでIBM CloudとGoogle Colabが接続されたことが確認できます。
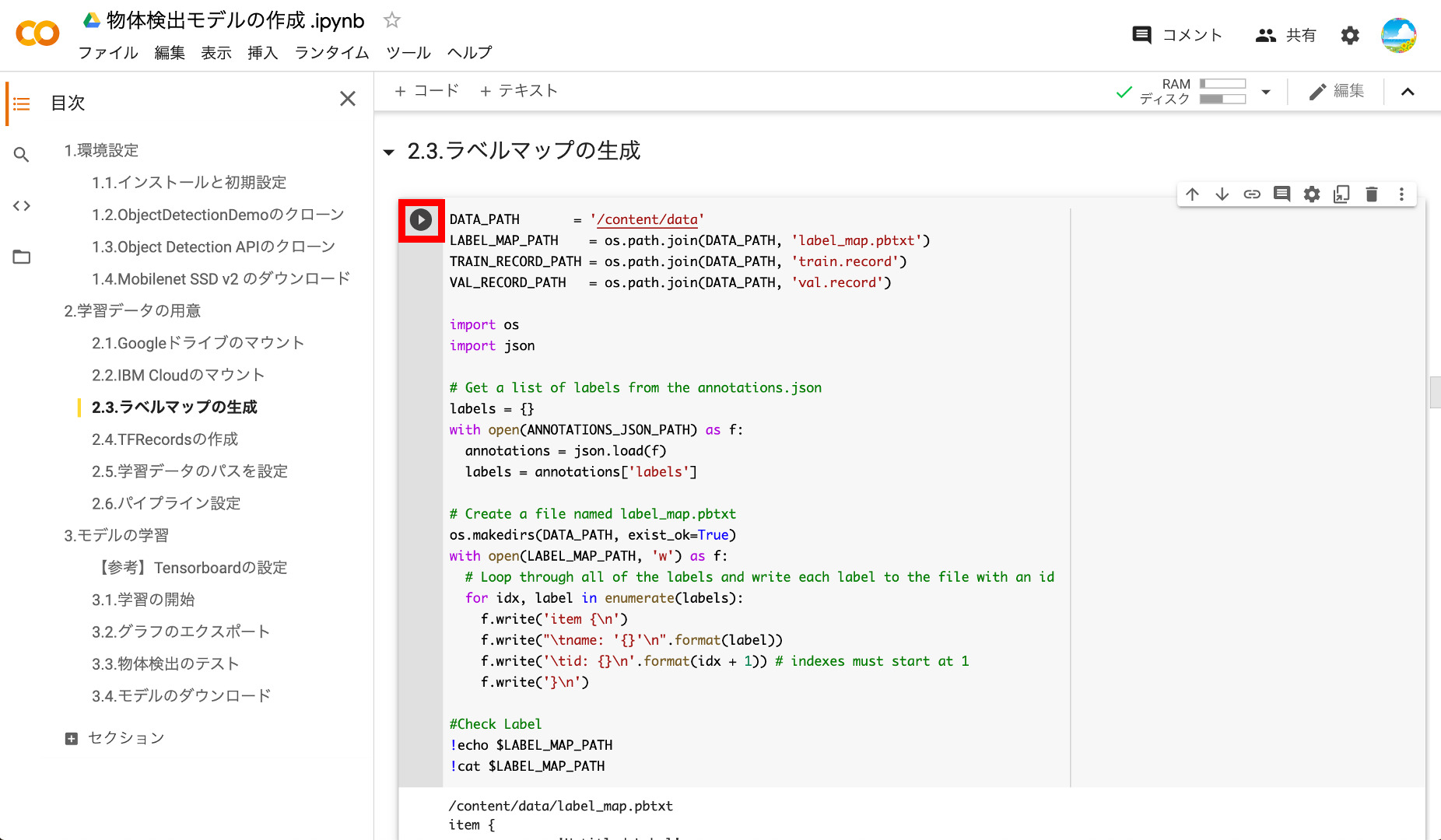
④ラベルマップの作成
次にラベルマップを作成します。ラベルの情報も_annotations.jsonに含まれているので、これを読み込んで作成していきます。
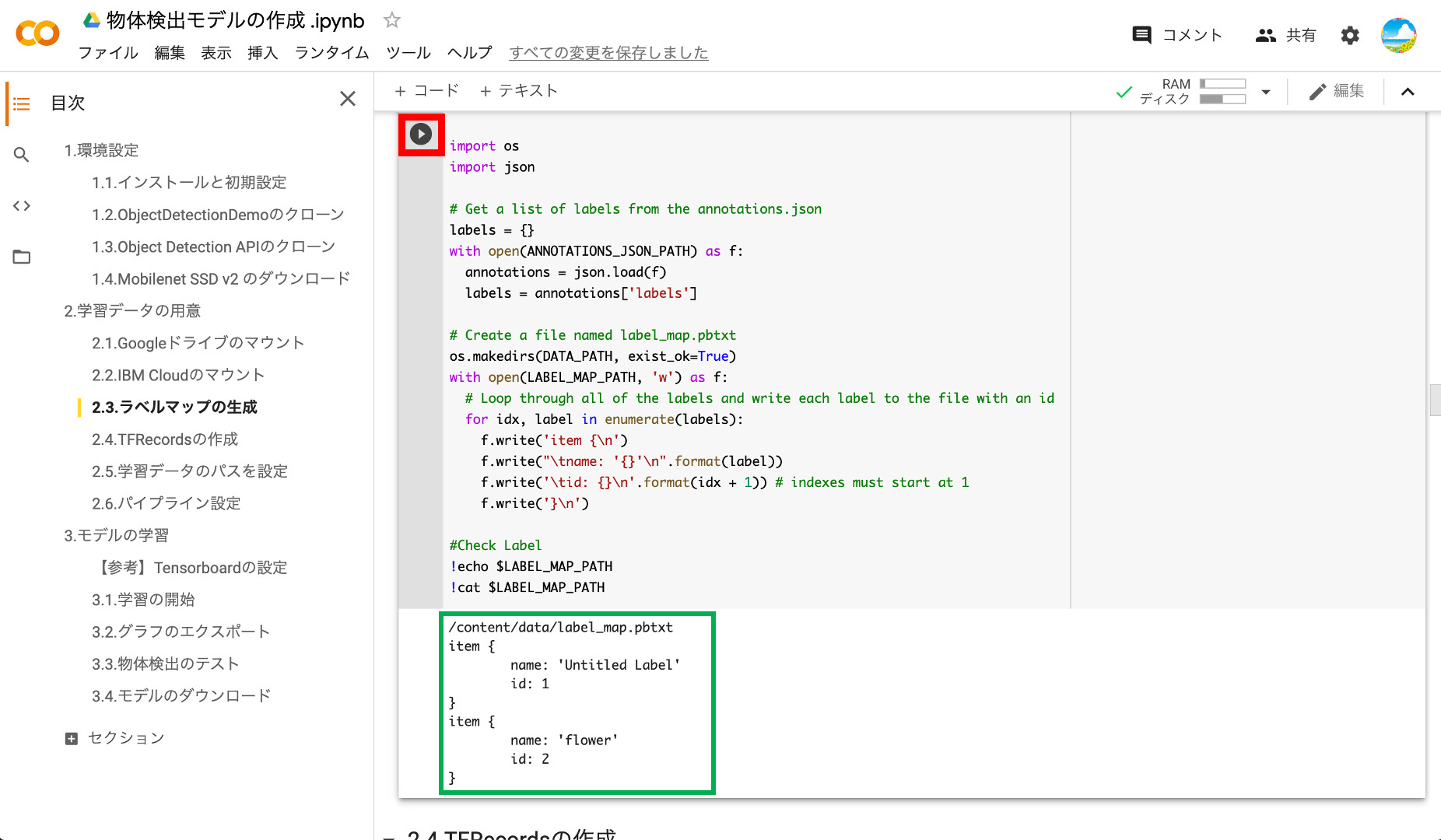
作成が終わると作成されたラベルマップが表示され、アノテーション時に入力したラベル名が確認できます。
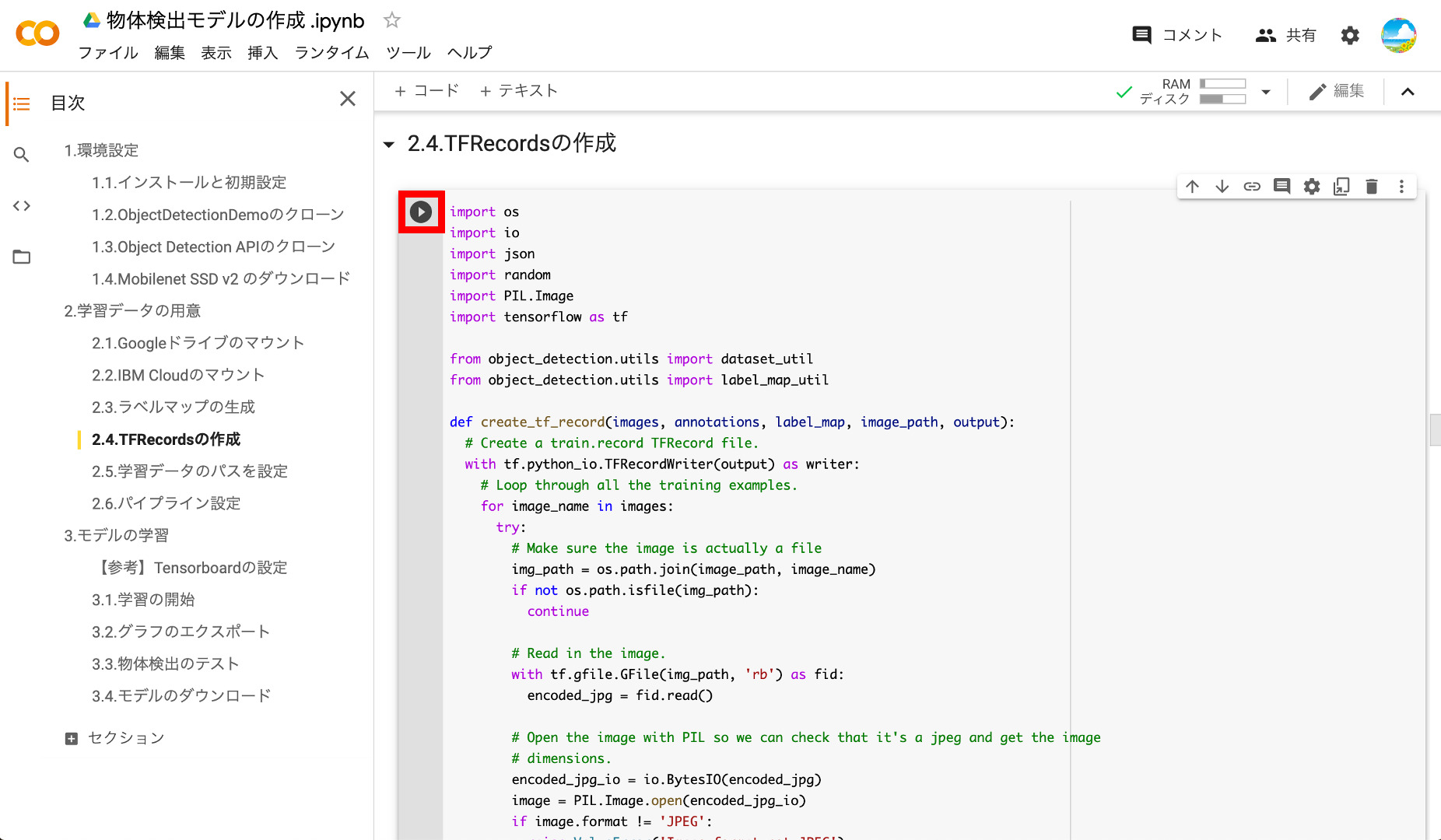
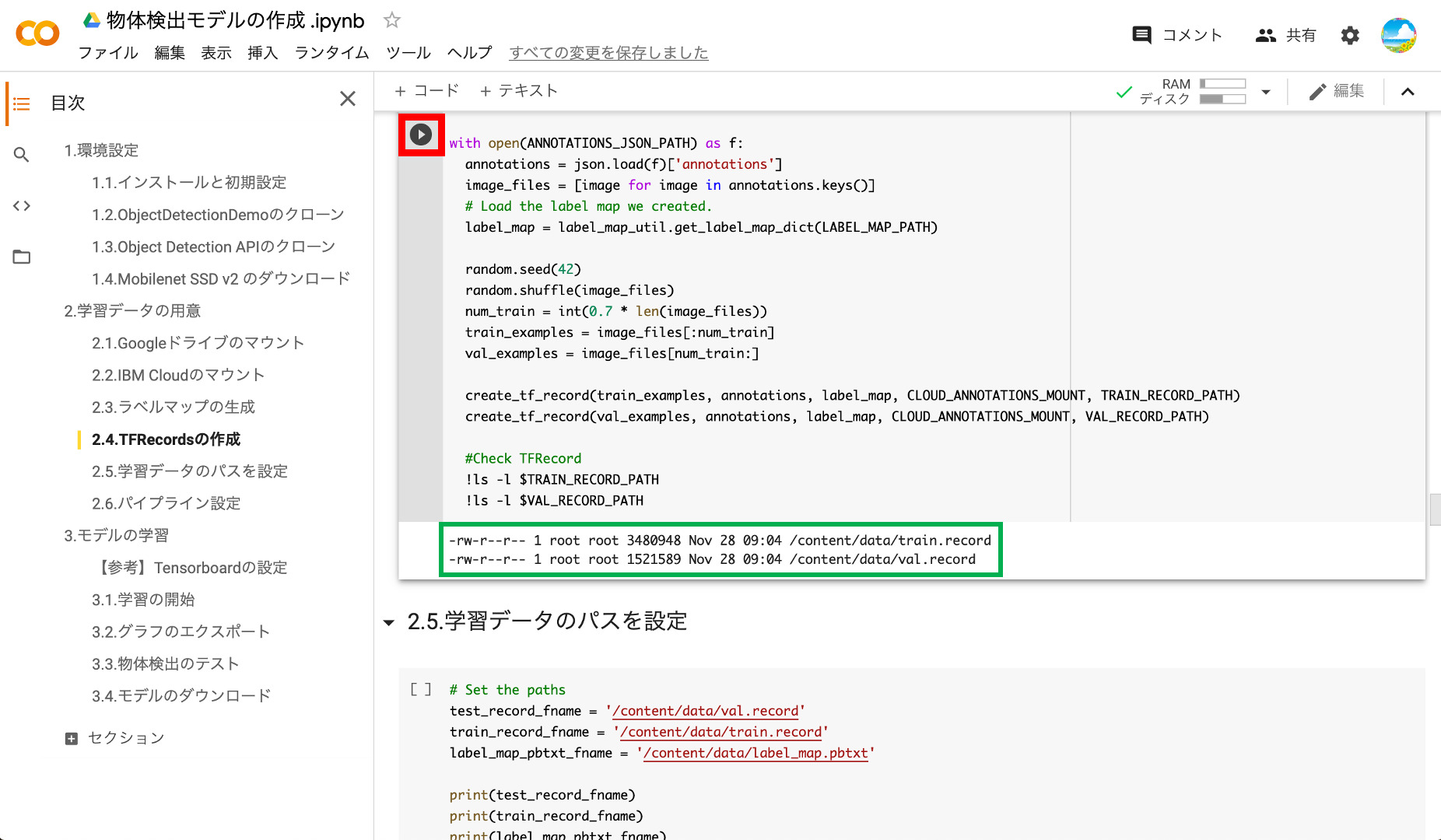
⑤TFRecordsの作成
それではモデル学習のインプットとなるTFRecordを作成しましょう。アノテーションしたデータの量にもよりますが、少し時間がかかります。
TFRecordの作成が完了すると、以下のように2つのレコードファイルが作成されます。1つ目のtrain.recordは学習用のレコードで、val.recordが検証用として使われるレコードです。
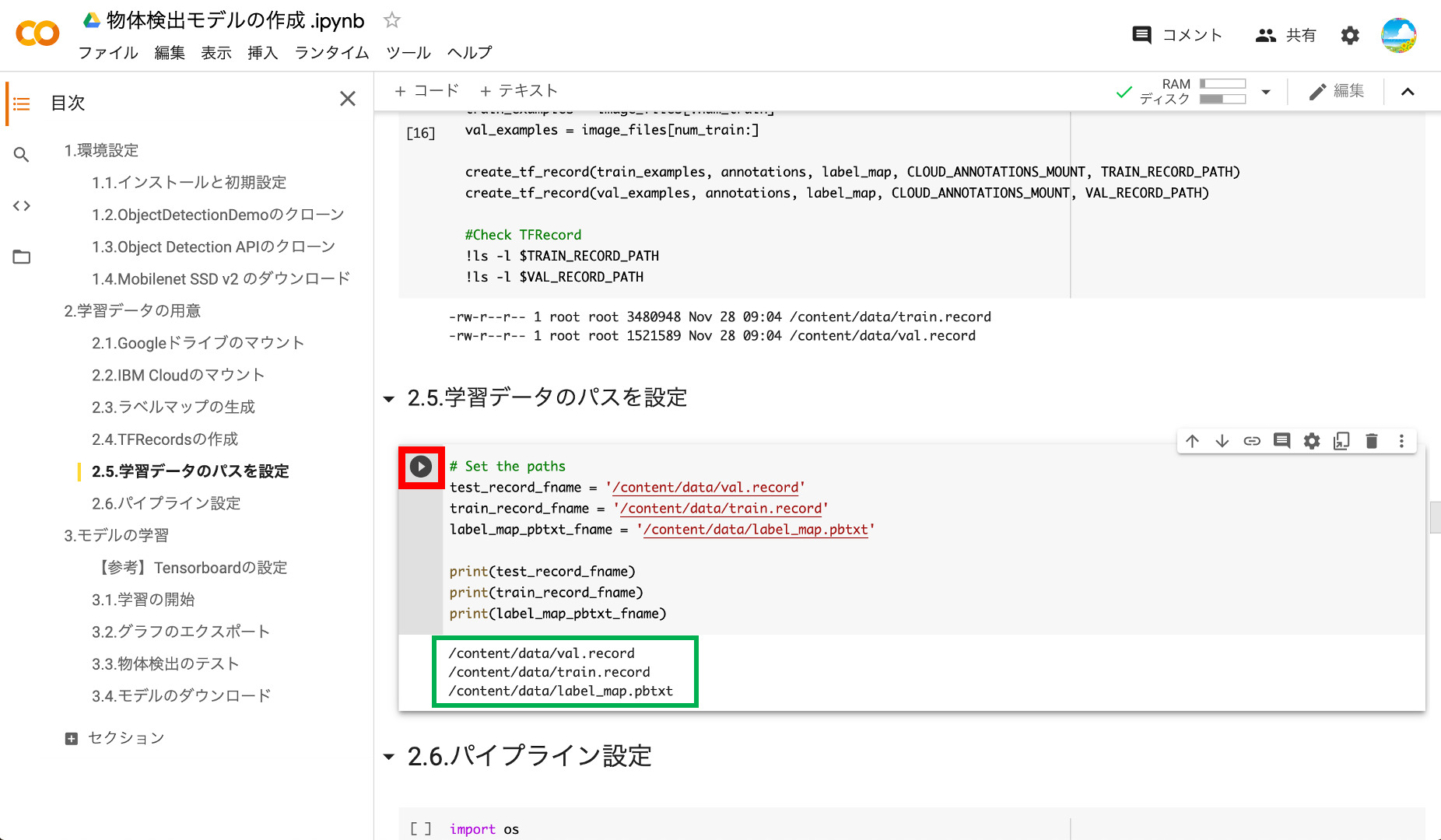
⑥学習用データのパスの設定
作成したラベルファイルとTFRecordのパスを変数に設定します。
⑦パイプラインの設定
最後に、モデル学習用の設定ファイル(パイプラインファイル)を作成します。
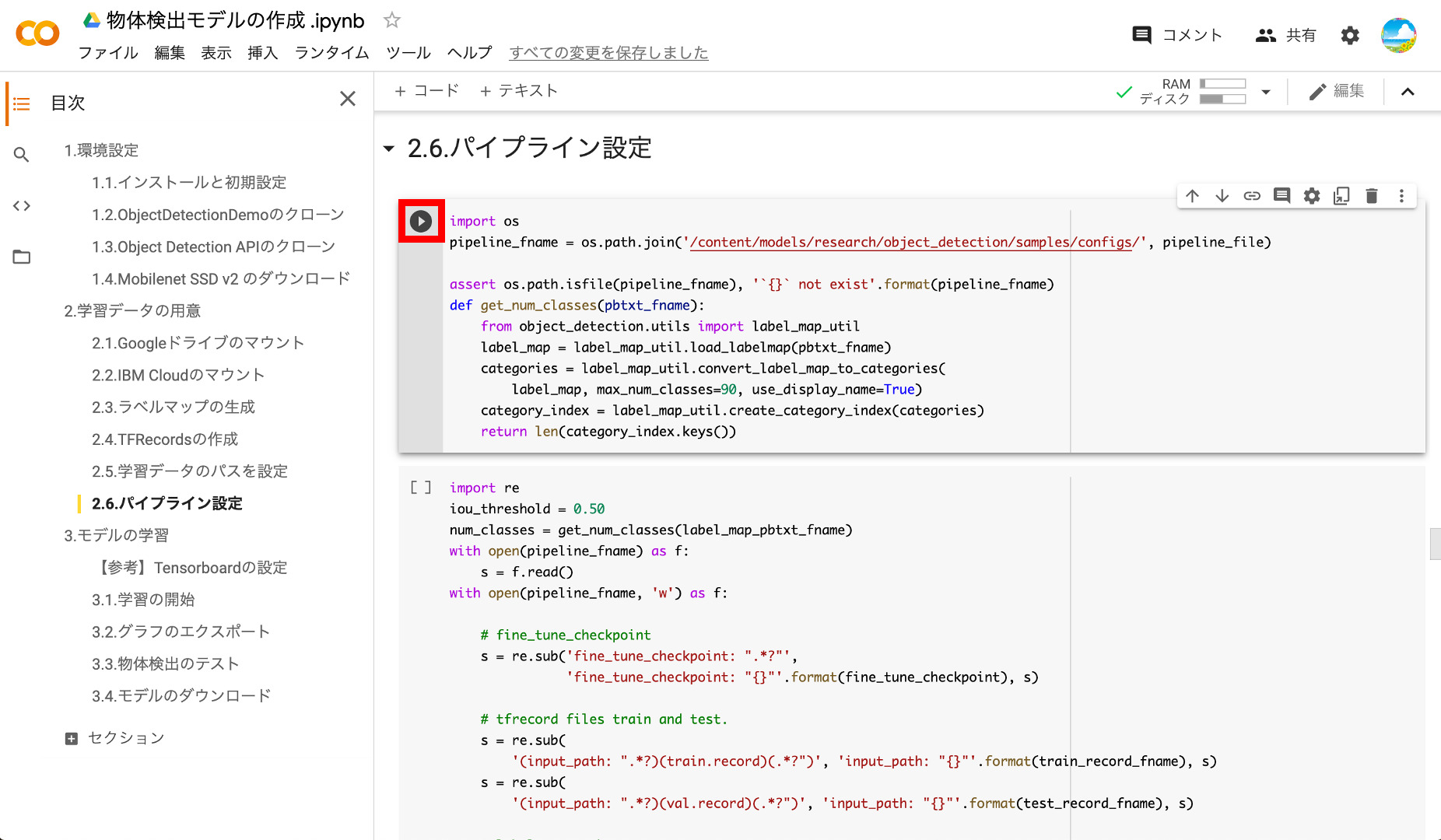
2つ目のブロックも実行します。
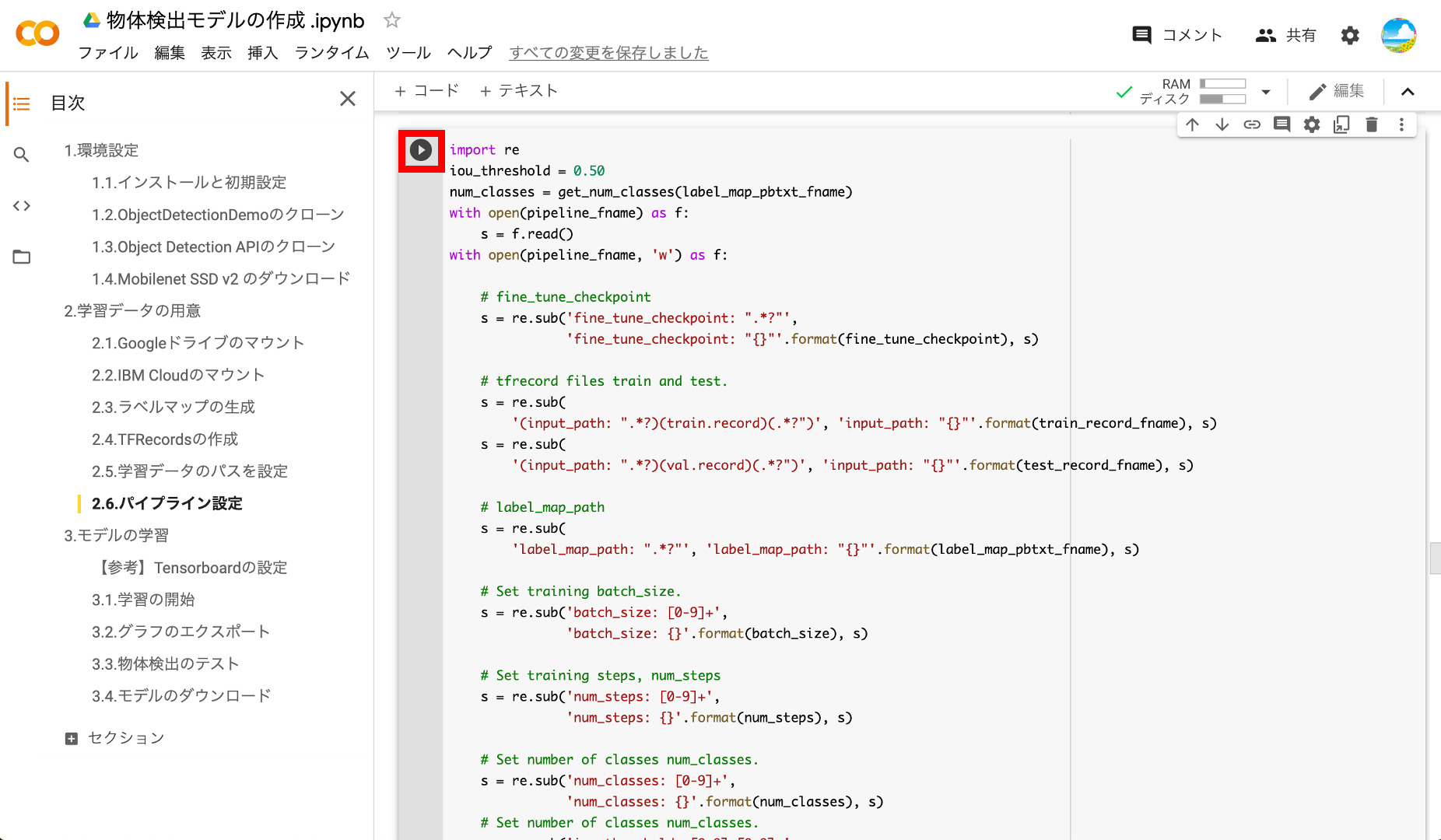
2つ目のブロックを実行するとパイプラインファイルの内容が表示されます。上で設定した学習ステップ数、チェックポイント、ラベルファイル、レコードファイルのパスが設定されていることを確認しましょう。
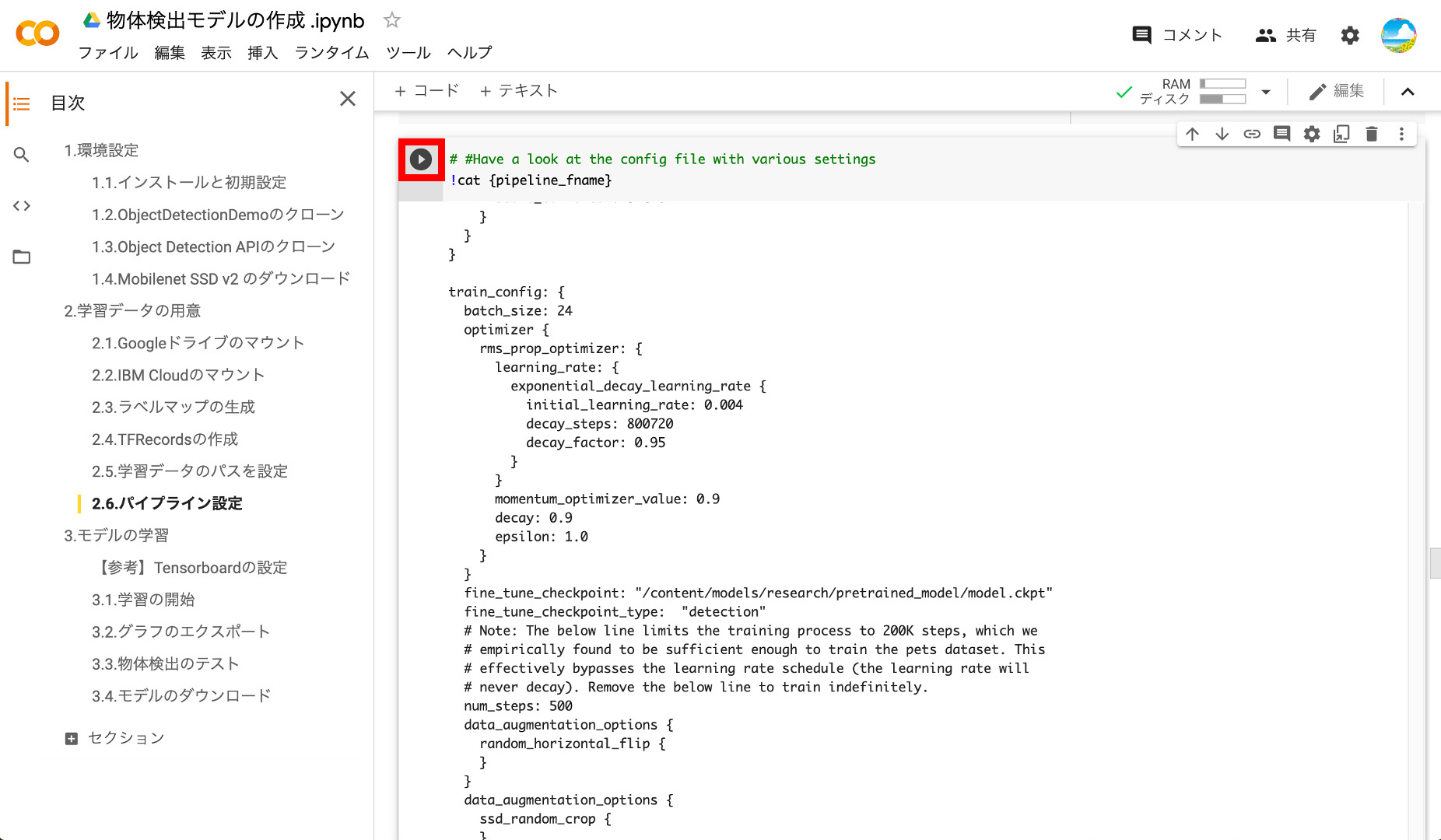
以上で学習データの用意は完了です。
モデルの学習
ここからは、いよいよTensorflow用の学習モデルを学習させていきます。
①Tensorboardの設定
500回の学習では5分程度で学習が完了してしまうので必要ありませんが、5000回を超える学習を行う場合には、時間がかかるので現在の学習状況が気になるところです。そこで、学習状況を可視化できるTensorboardを利用できるようにします。
操作は簡単、再生ボタンを押すだけです。ただし、以下のようにエラーになってしまう場合には、再実行しましょう!再実行の時には、上書きを確認されるので「A」と入力してエンターを押しましょう。
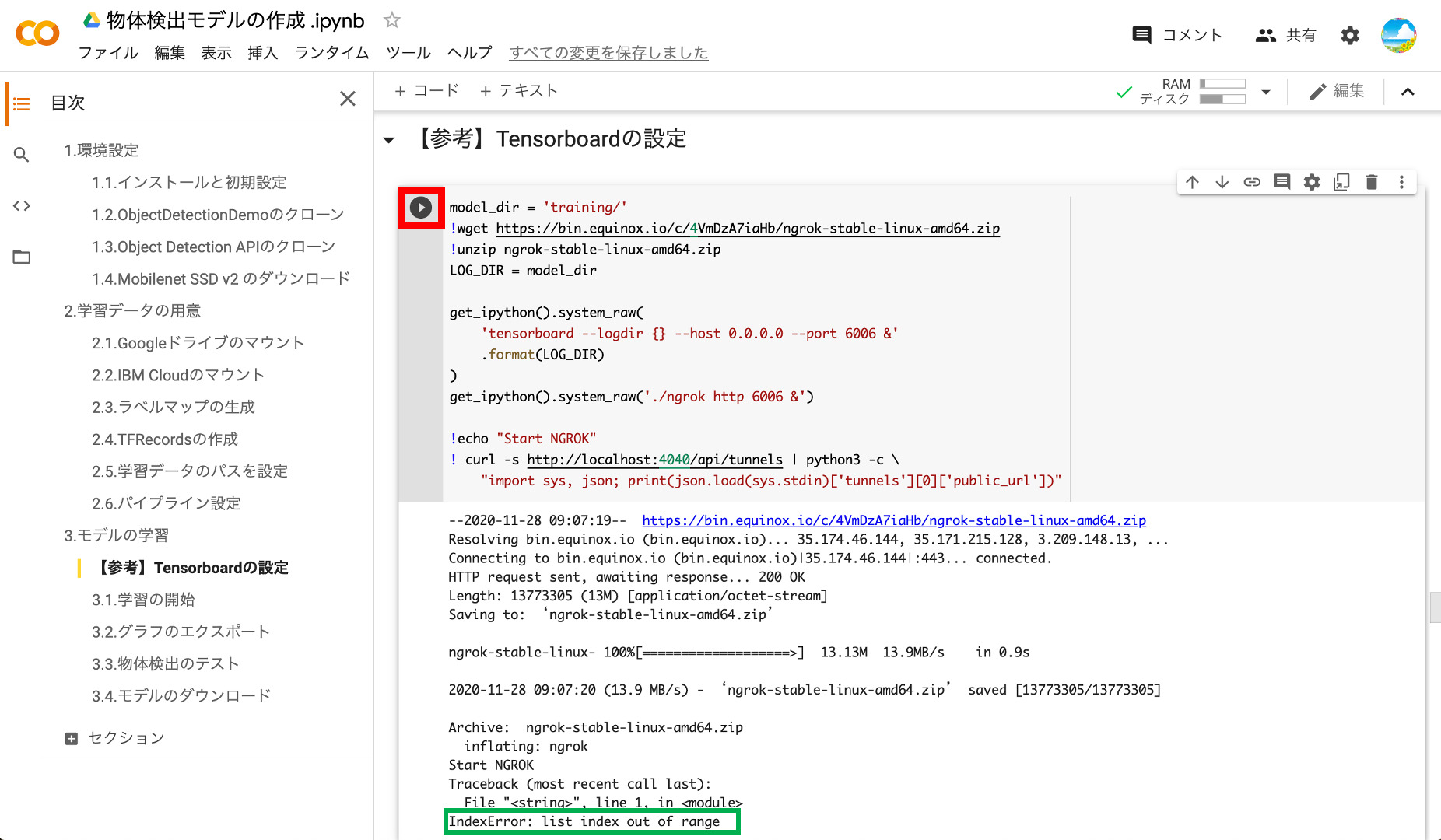
うまく行くと以下のように「https://xxxxxx.ngrok.io」とURLが表示されます。このタイミングでこのURLにアクセスしてもエラーになってしまいますので、次のステップで学習を開始したらアクセスしましょう。
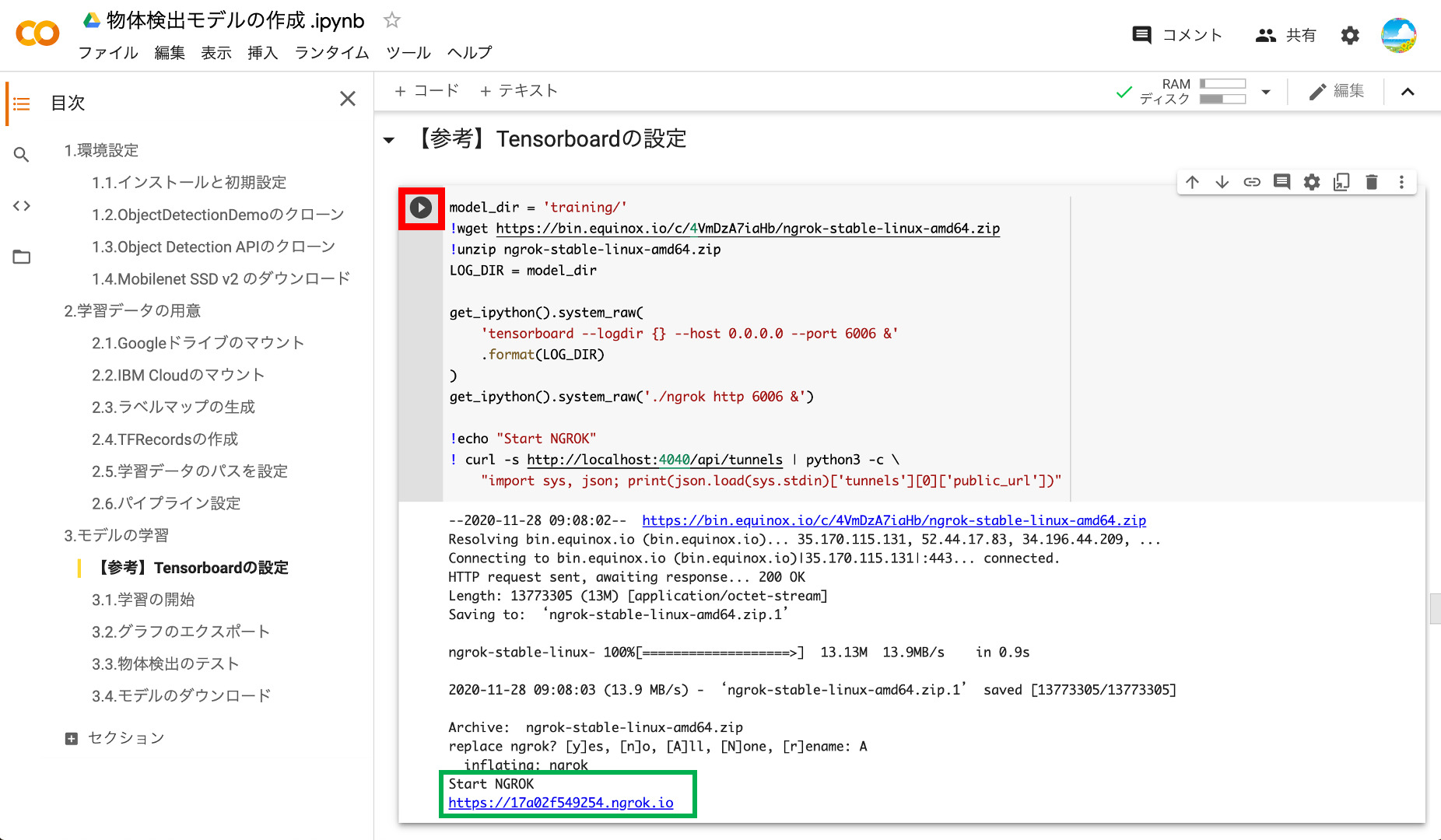
②学習のスタート
それでは、今回の本題のTensorflowのモデルの学習を行いましょう‼️
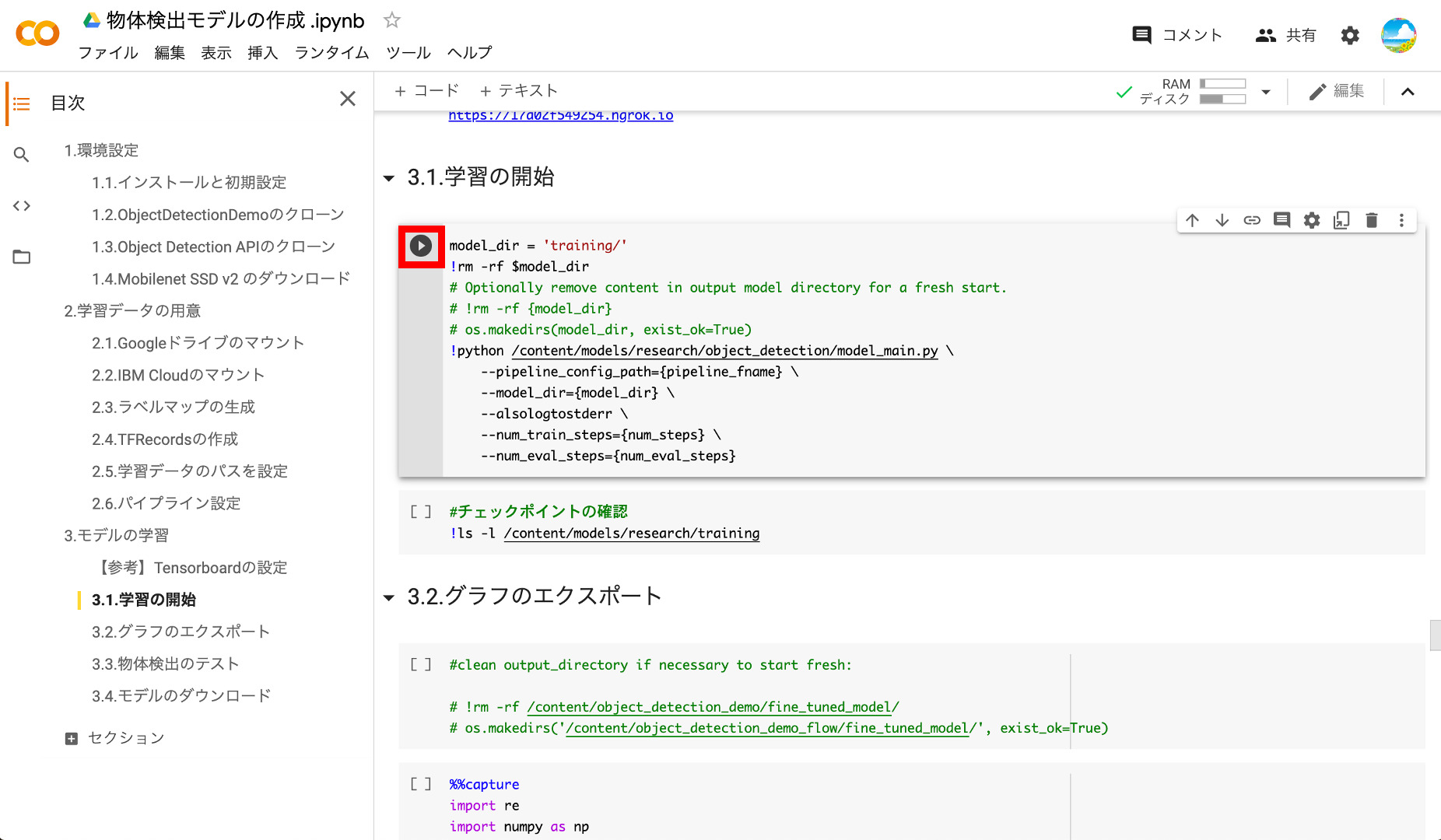
学習が開始されるとログが沢山表示されますが、Step=100という表示が500になったら完了です。500の場合で大体5〜10分かかります。途中経過を見るために、上で作成したTensorbordのURLにアクセスしましょう。
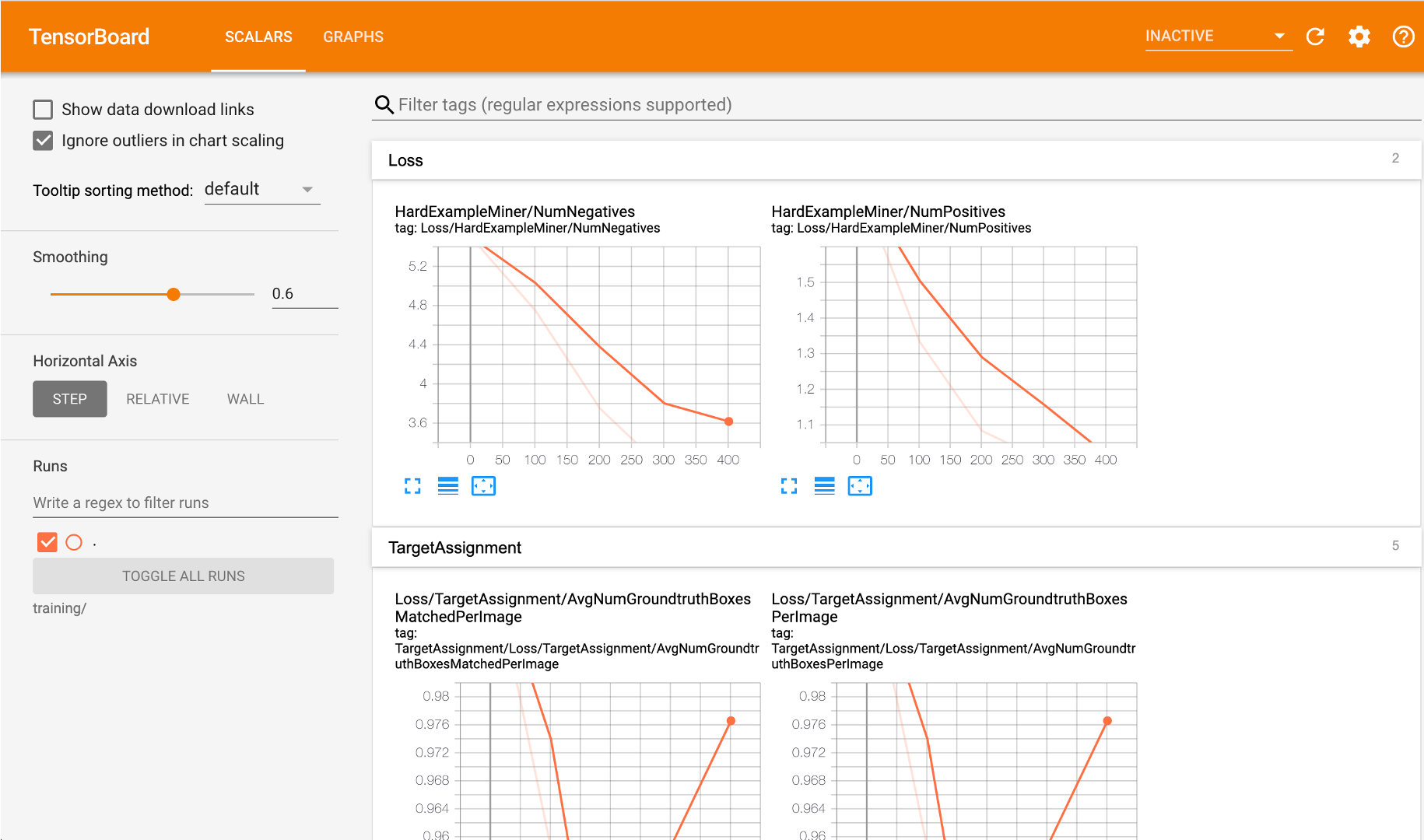
以下がTensorboadの画面です。500ステップの場合には、途中経過を確認するまでもなく、すぐに終わってしまいますが、5000回での実行では、Lossの値が段々と下がっている様子が確認できます。
Google clabの画面でStepの値が500になり、最後にログがだらだら流れると学習は完了です‼️
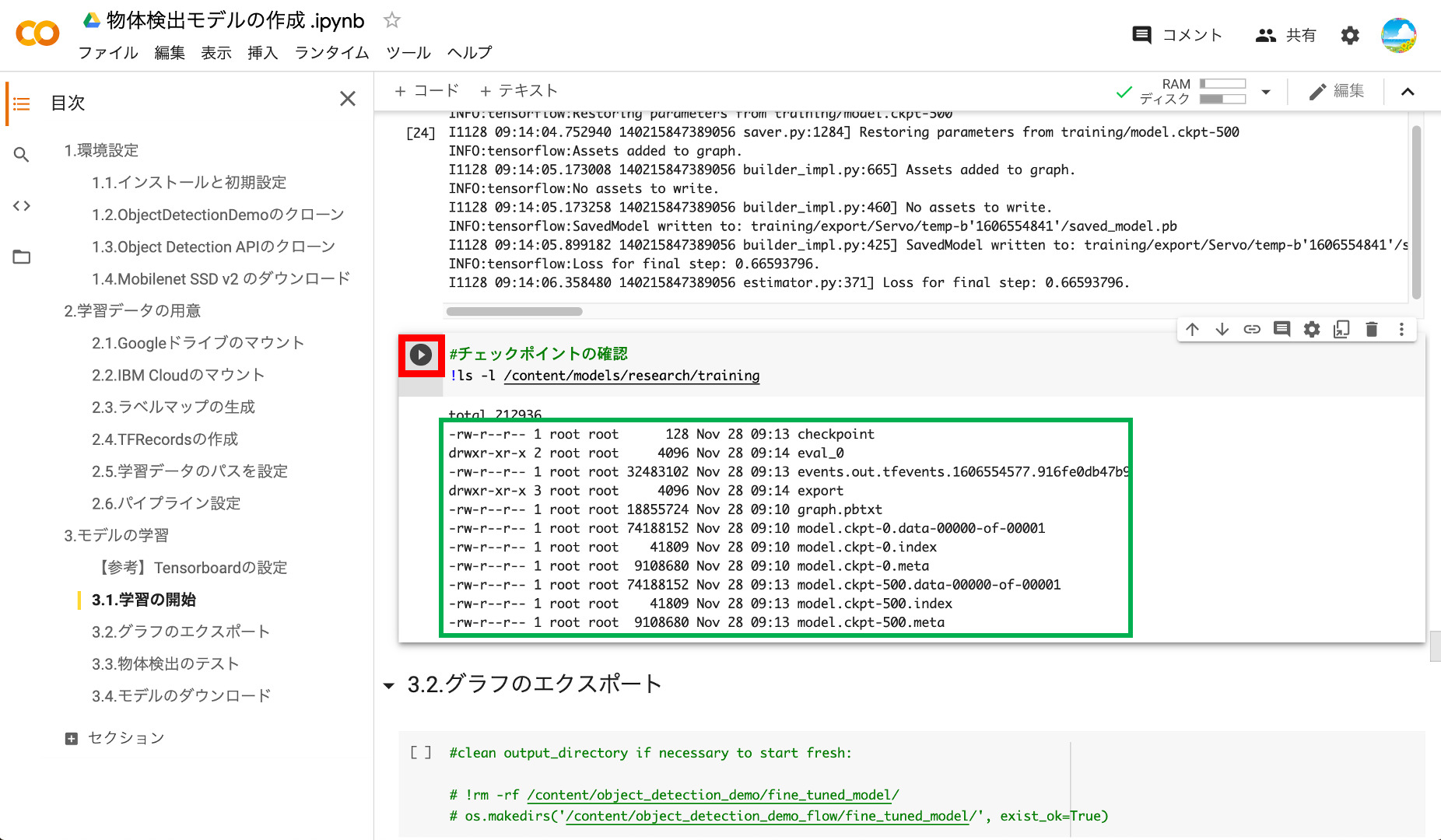
③チェックポイントの表示
学習が完了したら次のブロックを実行して、チェックポイントの情報を確認してみましょう。model.ckpt.500というものが確認できると思います。
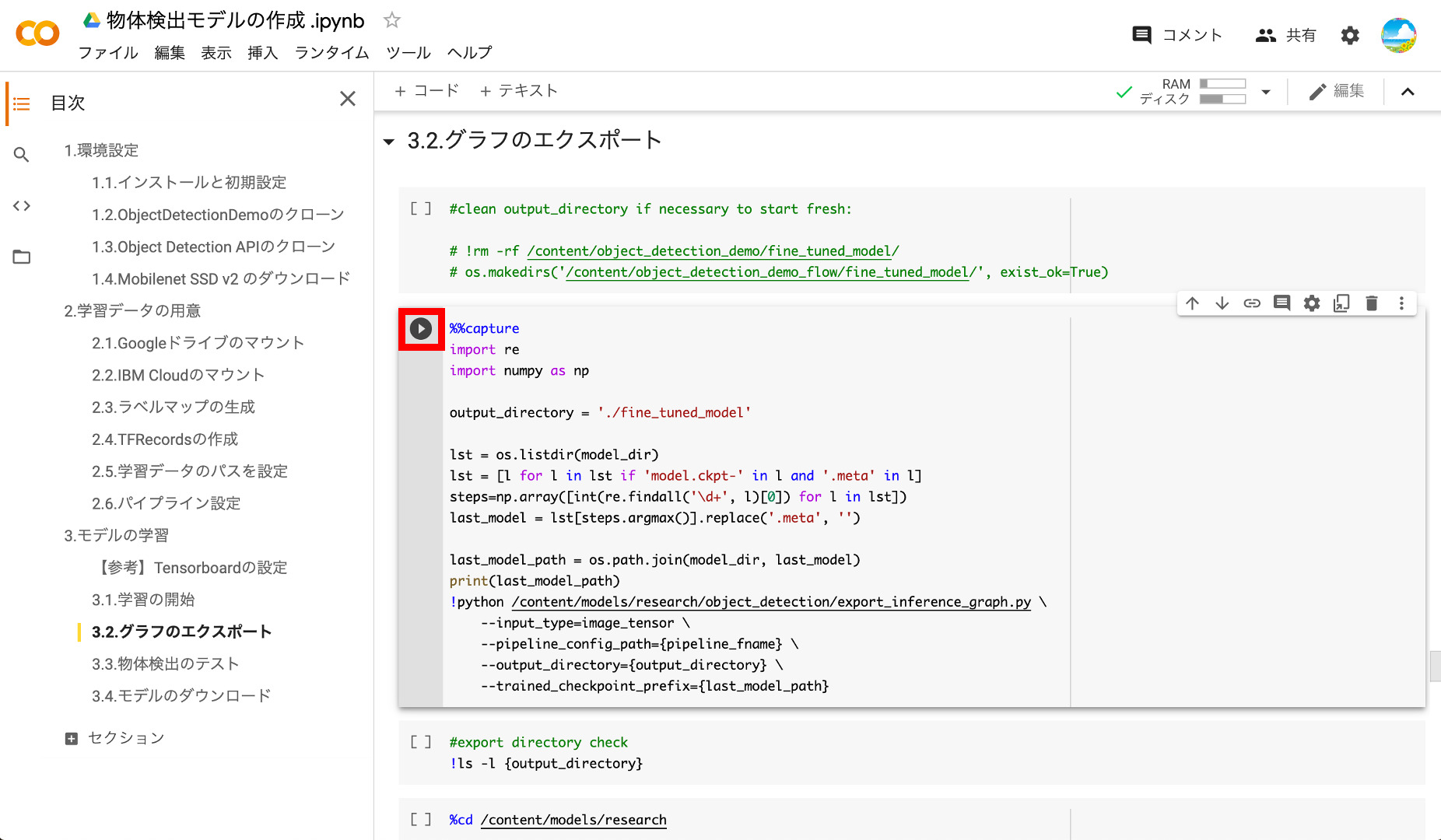
④グラフのエクスポート
学習したばかりのTensorflowのモデルは、学習させたマシンでしか利用できないので、エクスポート処理を行います。この処理にも少し時間がかかります。
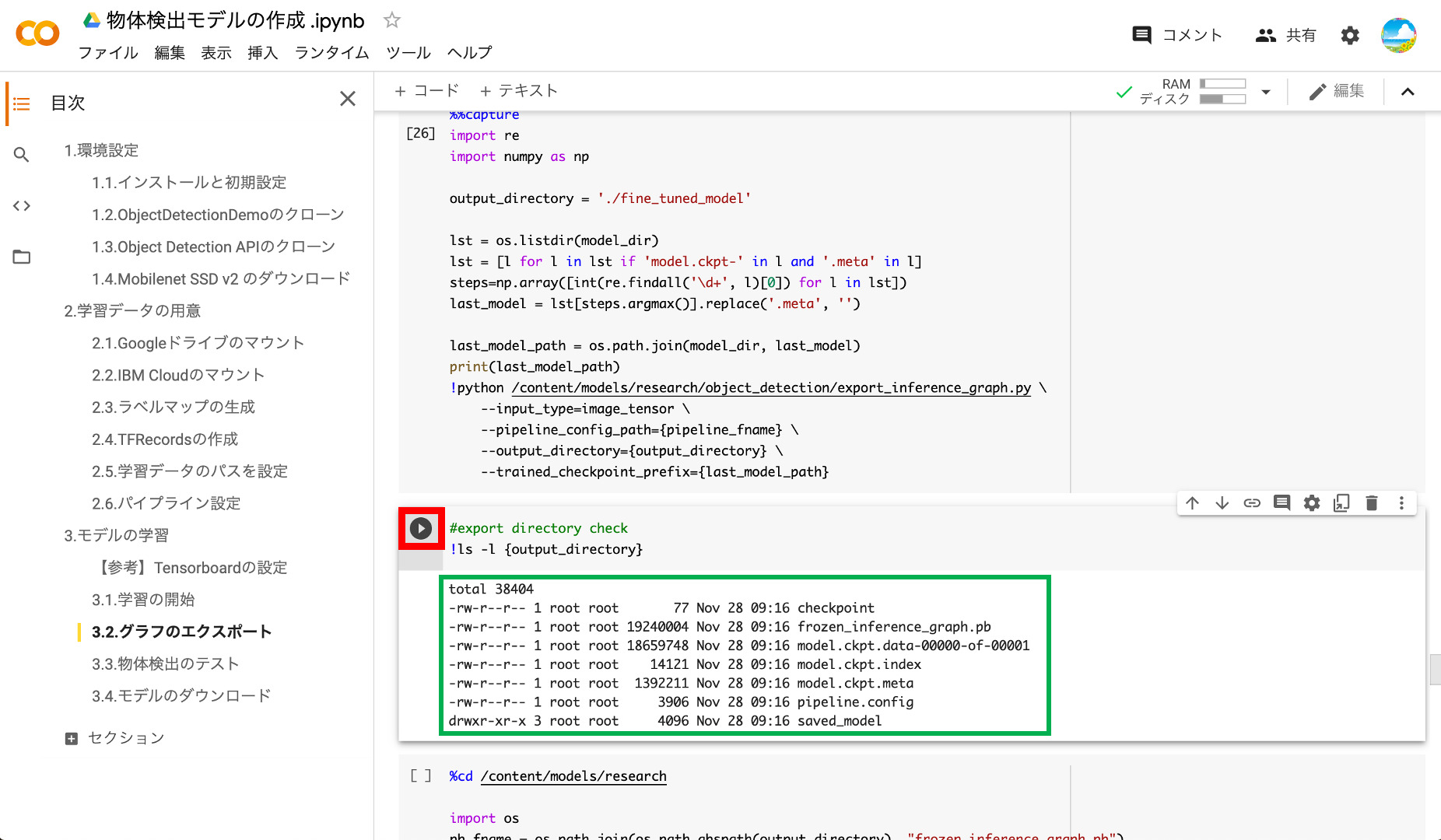
⑤エクスポートモデルの確認
エクスポートが完了したら次のブロックを実行して、エクスポートされたモデルを確認します。以下のようにsaved_modelやfrozen_inference_graph.pbが表示されていればOKです。
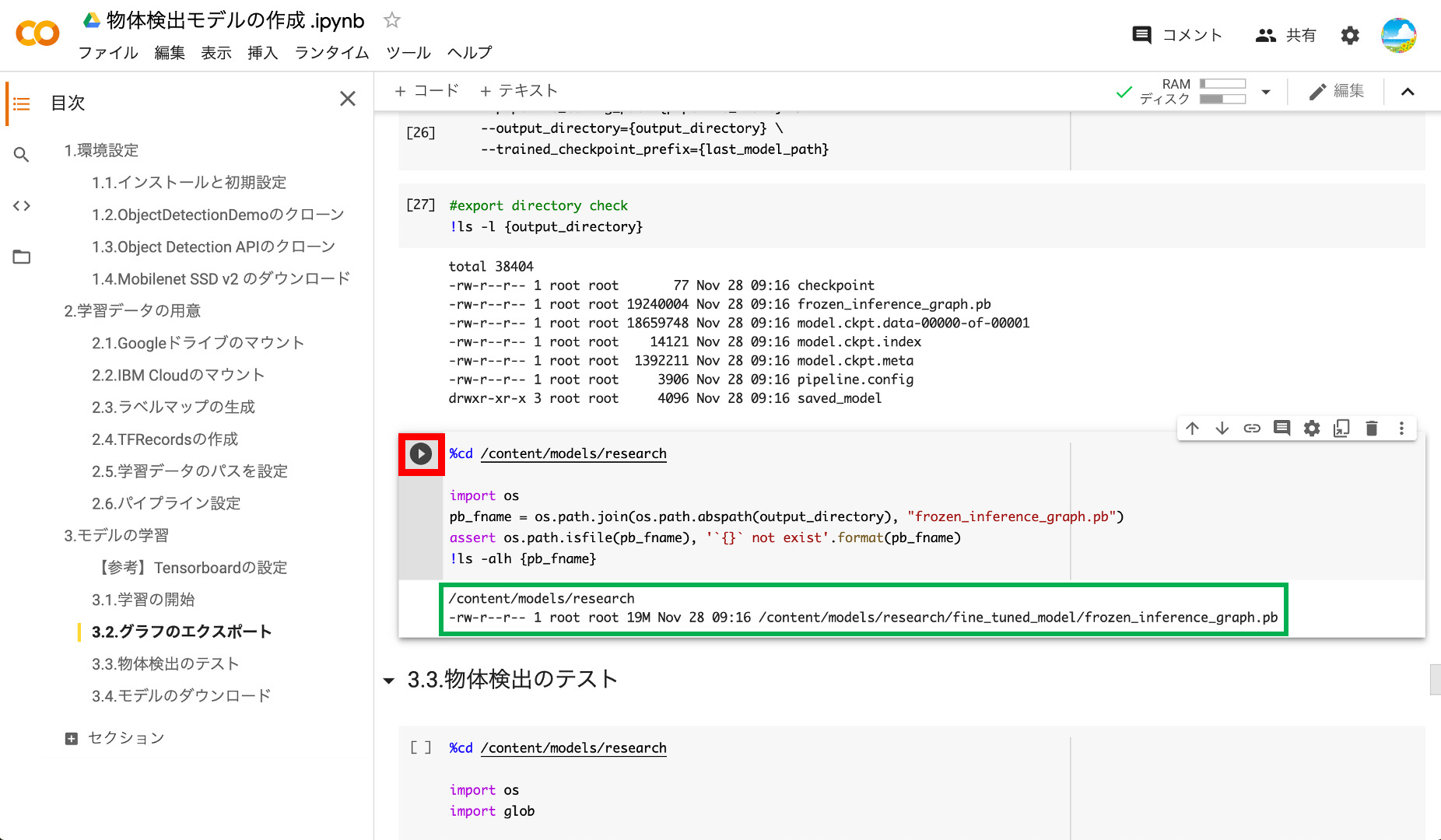
念のためfrozen_inference_graph.pbのフルパスも確認しておきましょう。
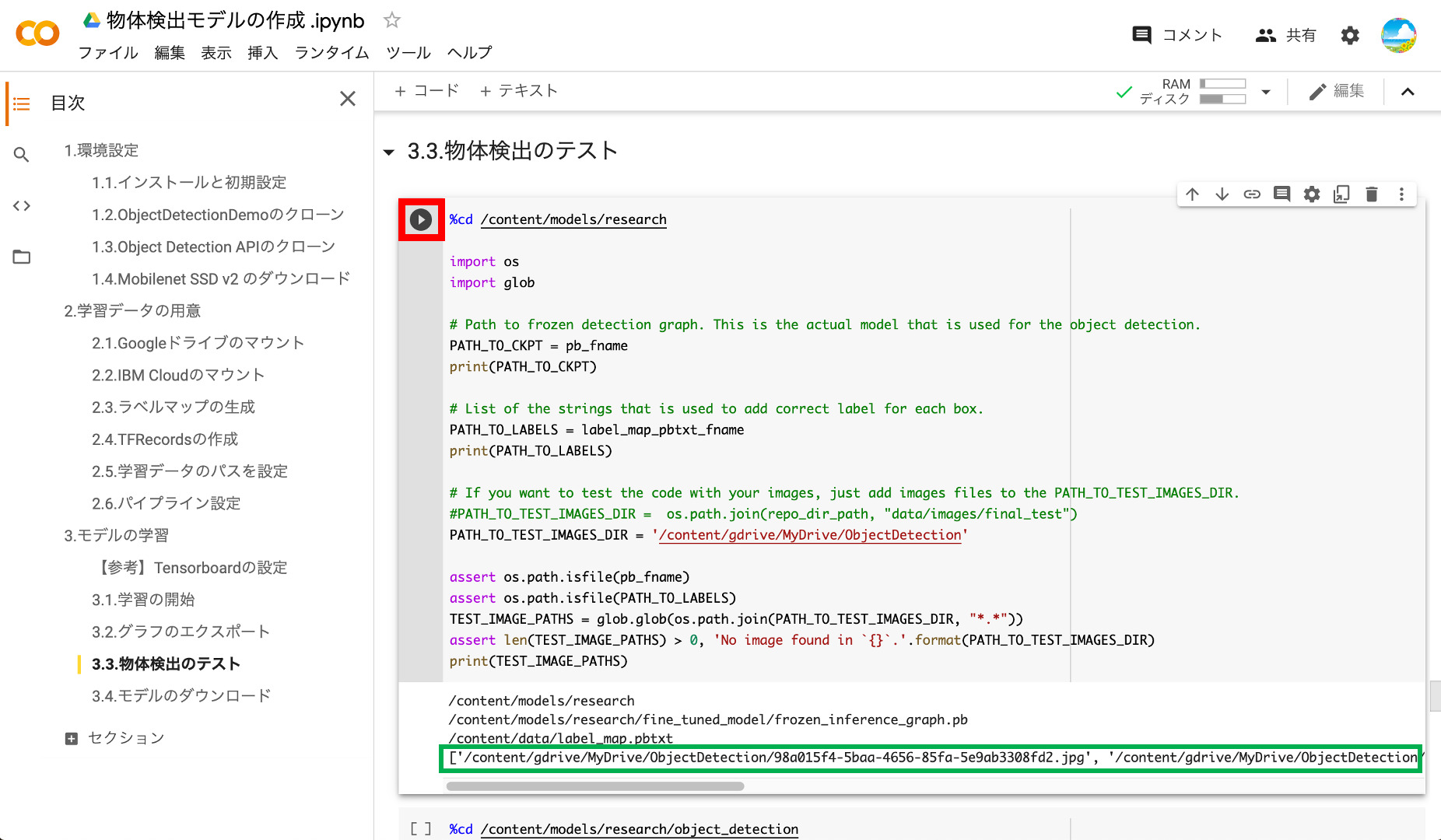
⑥テスト用画像の読み込み
次のステップでモデルのテストを行うために、テスト用画像を読み込みます。コードを実行して、GoogleDriveに格納したテスト用画像のファイル名が表示されればOKです。
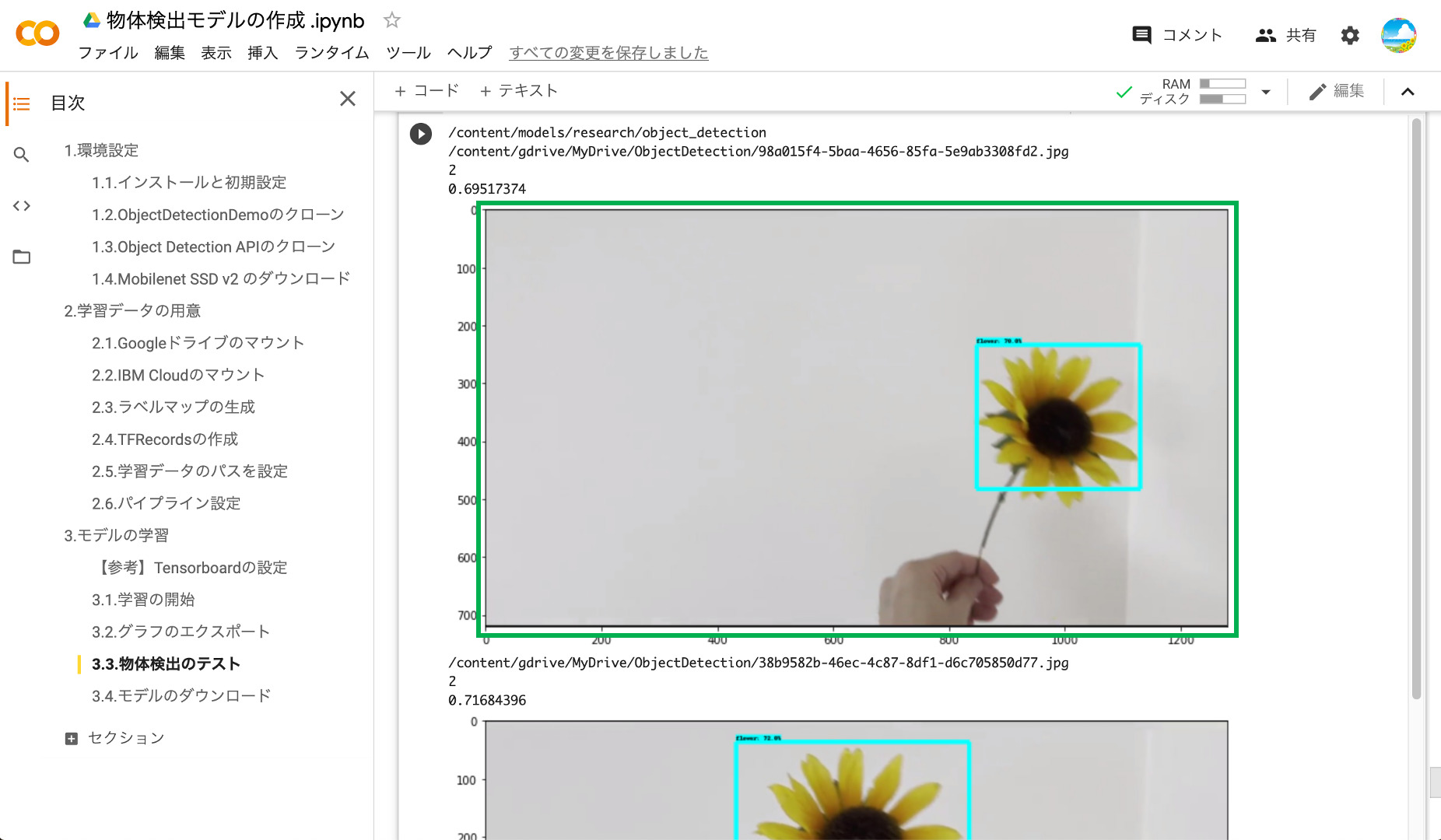
⑦学習モデルのテスト
それでは、学習したモデルを使って物体検出ができるかテストしてみましょう‼️テストのところのコードを実行します。すると、テスト用画像に対して物体検出が実行され、うまく行けば以下のように物体が検出されて表示されます‼️ちなみに、ファイル名の下の数字がラベルファイルで設定した検出物体のIndex番号、その下が確率です。
なお、実行しても画像が表示されない場合がありますが、その時はもう一度再生ボタンを押しましょう。
また、画像は表示されるものの、物体が検出されない場合は、学習のステップ数を増加させたり、アノテーションのデータ数を増やしたりしましょう。
⑧学習済モデルのダウンロード
最後に、学習済みのモデルをPCにダウンロードします。ダウンロードには少し時間がかかるので、気長に待ちましょう。
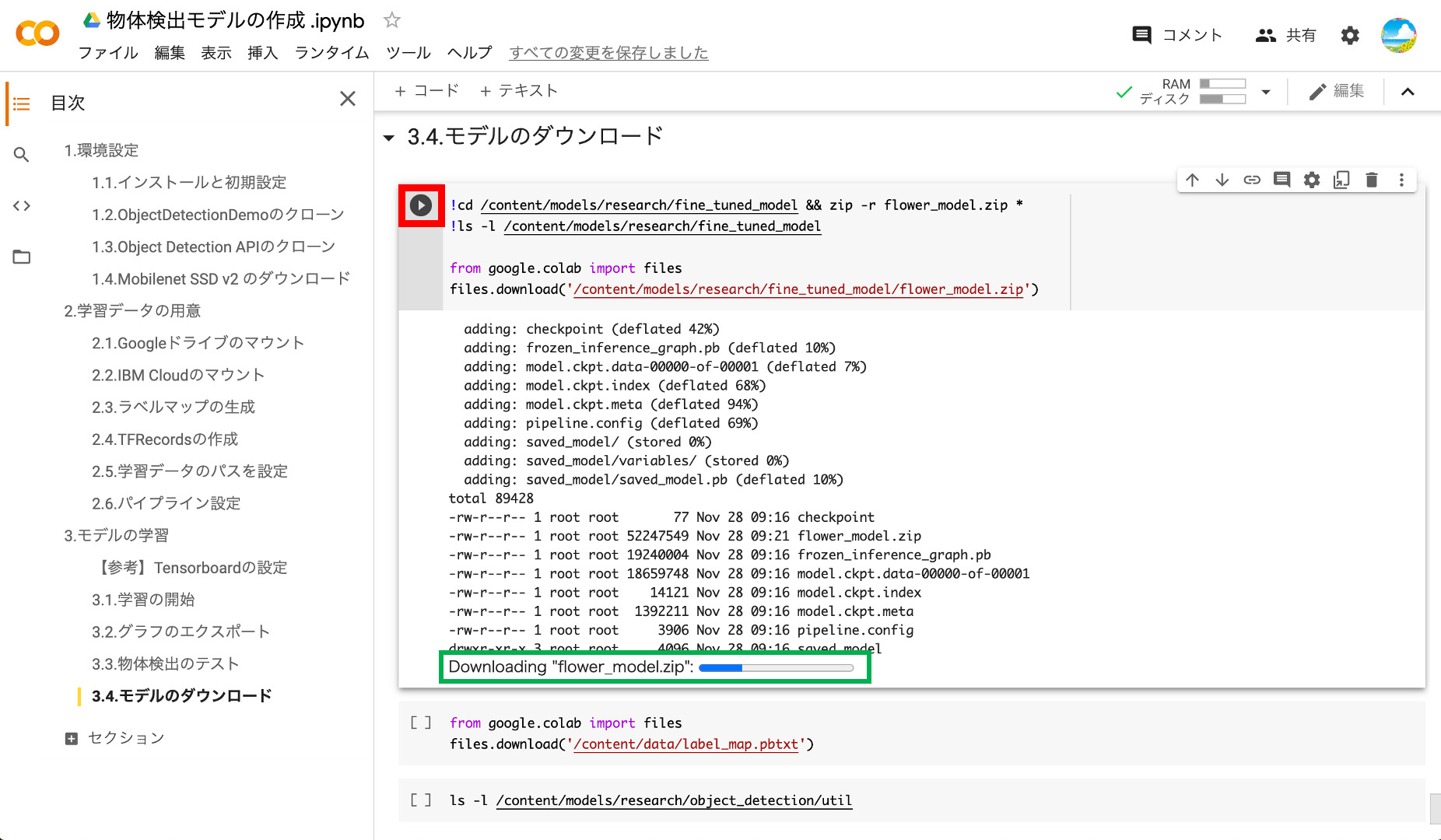
ダウンロードの準備が完了すると、以下のようにZIPファイルがダウンロードされます。
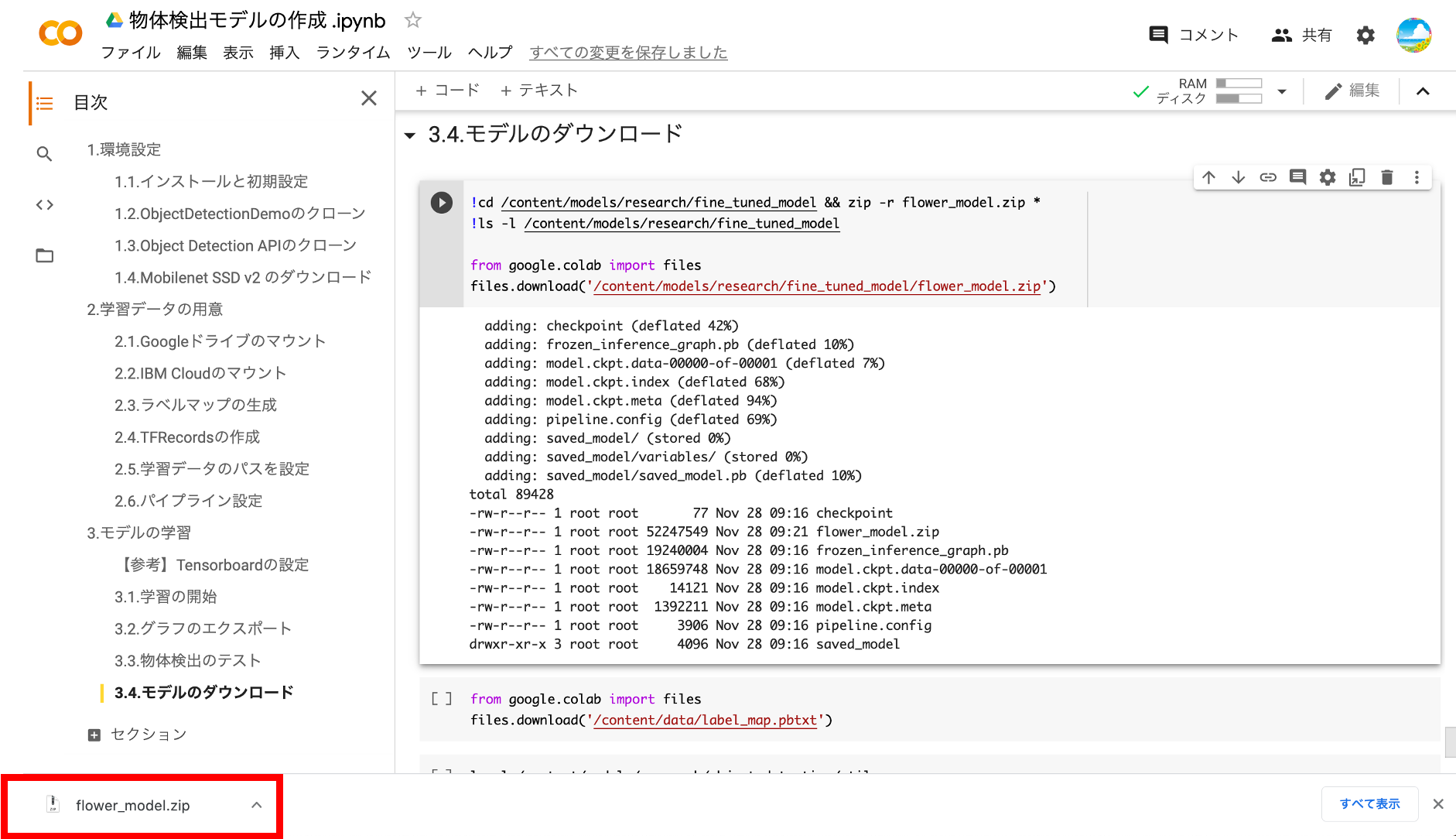
⑨ラベルファイルのダウンロード
ついでにラベルファイルもダウンロードしておきましょう。TensorRTでは使いませんが、念のため(笑)
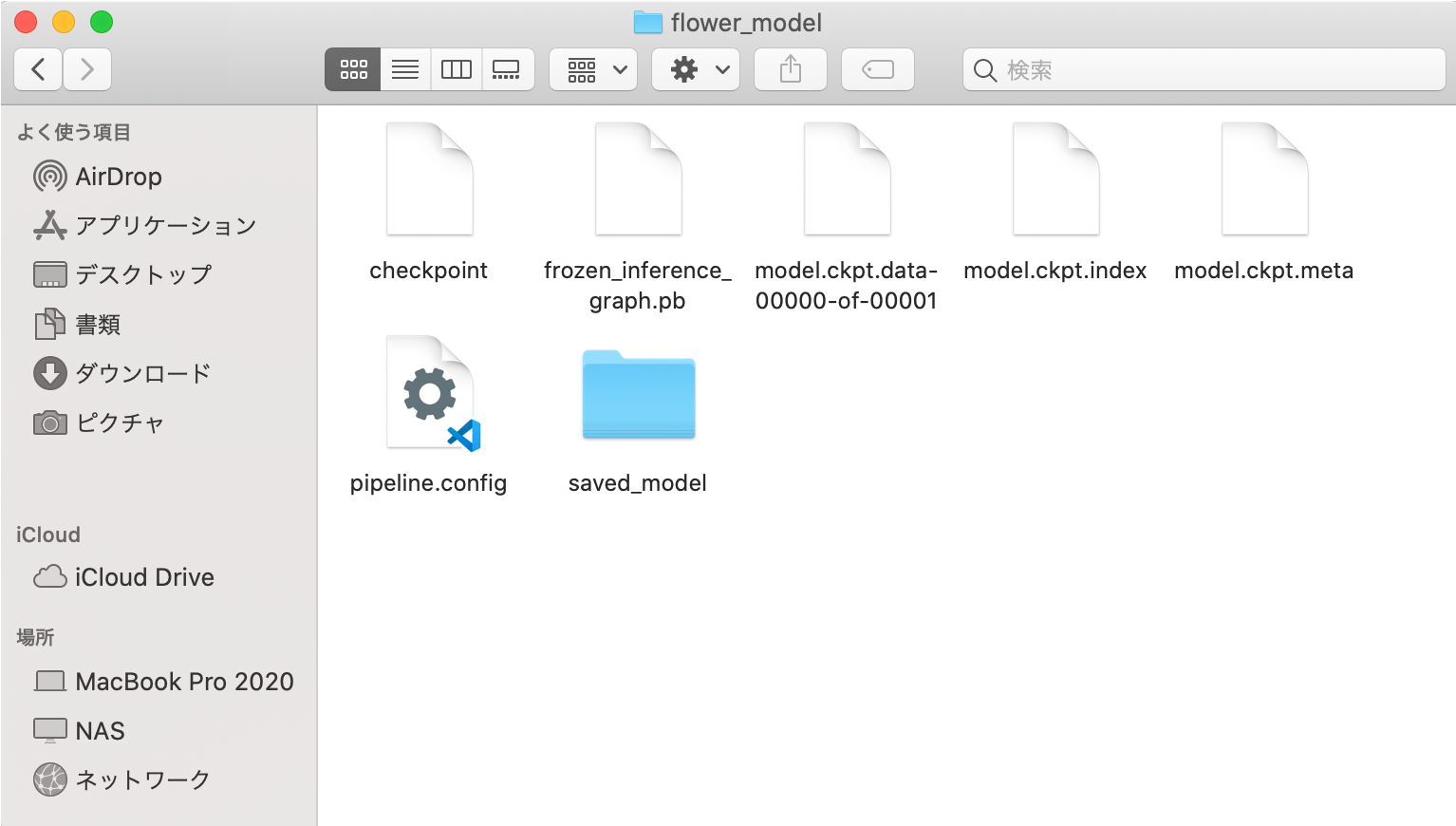
【参考】モデルファイルの内容確認
ダウンロードした学習済モデルのZIPファイルを解凍すると以下のファイルが含まれている事が確認できます。このファイルのうち「frozen_inference_graph.pb」が次のステップで使うファイルになります。
以上でGoogle Colabを使ったTensorflowモデルの作成は完了です。
おわりに
今回は、Jetson nanoで物体検出を行う連載記事の第2回目として、Google Colabを使ってTensorflowの学習モデルを作成することをやってみました。次回は、Jetson nanoにTensorRTなどをインストールして、物体検出を行う環境準備を行います。
第1回:IBM Cloud Annotationsを用いたアノテーション
第2回:Google Colabを用いたモデルの学習
第3回:Jetson nanoの環境構築 ←次回
第4回:DeepStreamアプリを使いこなす
第5回:学習モデルの変換と物体検出
関連記事



コメント