
はじめに
最近の画像認識&DeepLeaning技術の進歩はすごく、画像や動画の中から特定の物体を検出し認識する事が可能になりました。しかもサーバなどの強力なCPU+GPUを積んだマシンででなくても、Rasberry Pi(ラズパイ)などの小さなボードコンピュータでもできてしまいます!
このブログではGPUを搭載したJetson nanoでの物体検出の方法をご紹介しましたが、今回はより安価なRasberry Piを使った方法をご紹介します。Raspberry Piでは、少しでも動作を早くするためにTensorFlow Lite(tflite)を使いますが、これが結構大変でしたので、その方法をまとめておきます。
今回やりたい事は、以下の動画のように、オリジナルの学習データを使って、動画中の物体を検出&認識することです。ただ、動画を見ていただければ分かる通り、Raspberry Piでは2FPSぐらいが限度のようです💦高速化の方法は、別途検討して行きたいと思います。
物体検出の実現方法
Rasberry Piで物体検出を行うために、今回は以下のように実現しました。Rasberry Piが必要な以外には、無料のCloud Serviceで大体のことができてしまいます。すごい世の中ですね☺️

①アノテーション:検出したい物体について、モデル学習用の教師データを作成します。
②学習:教師データから物体の特徴を学習したPBモデルを作成します。
③環境構築:Raspberry PiにOSやTensorFlow Liteなどをインストールします。
④物体検出:学習済のモデル使って物体を検出します。
実現に向けた連載
Raspberry Piを用いた物体検出は、思った以上に多くの作業が必要で、とても1つの記事では書ききれないので以下の4回に分けて記載したいと思います。
第1回:IBM Cloud Annotationsを用いたアノテーション ←この記事
第2回:Google Colabを用いたモデルの学習
第3回:Raspberry Piの環境構築
第4回:オリジナルモデルを用いた物体検出
第1回:IBM Cloud Annotationsを用いたアノテーション
第1回では、学習モデルを作成するためのインプットとなる、教師データを準備していきます。この教師データの作成はアノテーションと言い、IBM Cloud Annotationsサービスを使うことで、簡単に学習データを作成できます。しかも無料です❗️便利な世の中ですねー😍
※この内容はJetson nanoの場合と同じです。
用意するもの
Raspberry Piを用いた物体検出を行うために必要なものは以下の3点です。
①Raspberry Pi
まずは、Raspberry Piが必要です。今回はRaspberry Pi 4Bの2GBモデルを利用します。

②カメラモジュール
Raspberry Piで動画を撮影するためのカメラモジュールです。今回は家にあった以下のものを使いました。Raspberry Pi 3B対応としか書いてありませんが、4Bでも問題なく使えました。

③Googleアカウント
Google ColabとGoogle Driveを利用するために、Googleアカウントが必要です。持っていない人はいないですよね?

④IBM Cloudアカウント
最後にIBM Cloud Annotationsを利用するためにIBM Cloudのアカウントが必要です。無料カウントで問題ないので、持っていない人は登録しましょう。

Raspberry Piを用いた物体検出に必要なものは、以上の4点です。
検出物体の動画準備
①検出物体の決定
まずは、検出したい物体を決めましょう。私は、家にあった「ひまわり」の造花で実験しました🌻

②物体の動画と画像の撮影
物体が決まったら、その物体の動画を撮影しましょう。スマホで撮影すればOKです。いろいろな角度でも検出できるように、物体を動かしながら撮影するのがポイントです。動画の時間は1分もあれば十分な量になります。以下の動画のイメージです。また、テスト用に物体の写真を10枚程度とっておきましょう。
③動画データの変換
IBM Cloud Annotationsでは、扱える動画の形式が限られているので、動画がH264エンコードのmp4形式でない場合は、動画の変換を行います。私は、ここでハマって半日を無駄にしました💦
Macの場合はに、以下のツールが無料で使えるので、お勧めです。
https://apps.apple.com/jp/app/フリー-mp4-変換/id693443591?mt=12
変換方法も簡単です。画面右上の「ファイルを追加」からiPhoneで撮影したMOVファイルを選択し、画面の下で変換形式を選択して。「変換」ボタンを押すだけです‼️
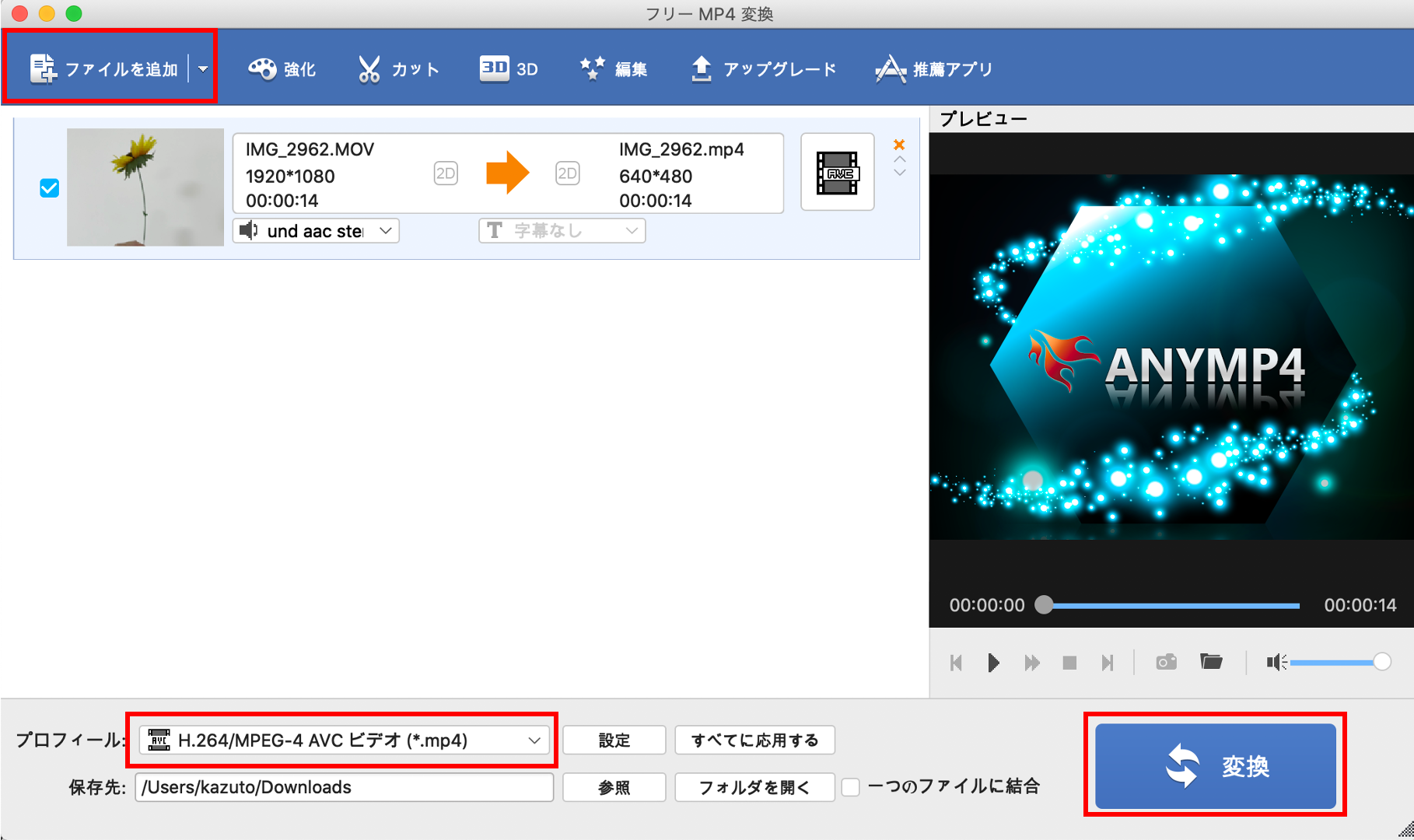
これで検出物体の動画の準備は完了です。
Object Strageの準備
IBM Cloud Annotationsを利用するためには、動画や画像ファイルを格納するストレージを予め準備しておく必要があります。無料のストレージで十分なので、まずはObject Strageを設定します。
①IBMクラウドにログイン
まずは、IBM Cloud「https://www.ibm.com/jp-ja/cloud」にアクセスしてログインします。ログインIDを作成していない人は作成しましょう。
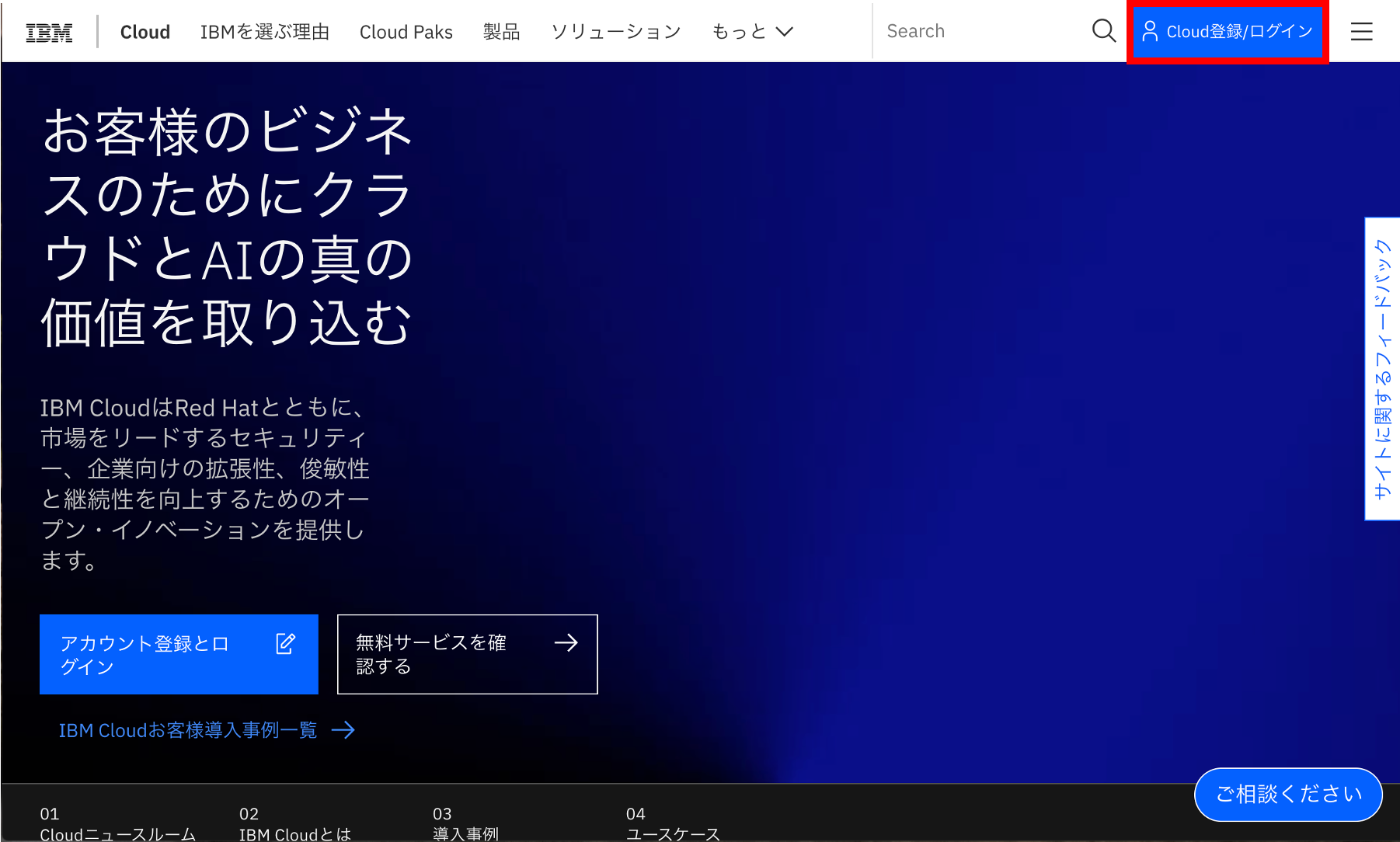
②リソースの作成
IBM Clouldのダッシュボードの、右上にある「リソースの作成」ボタンをクリックします。
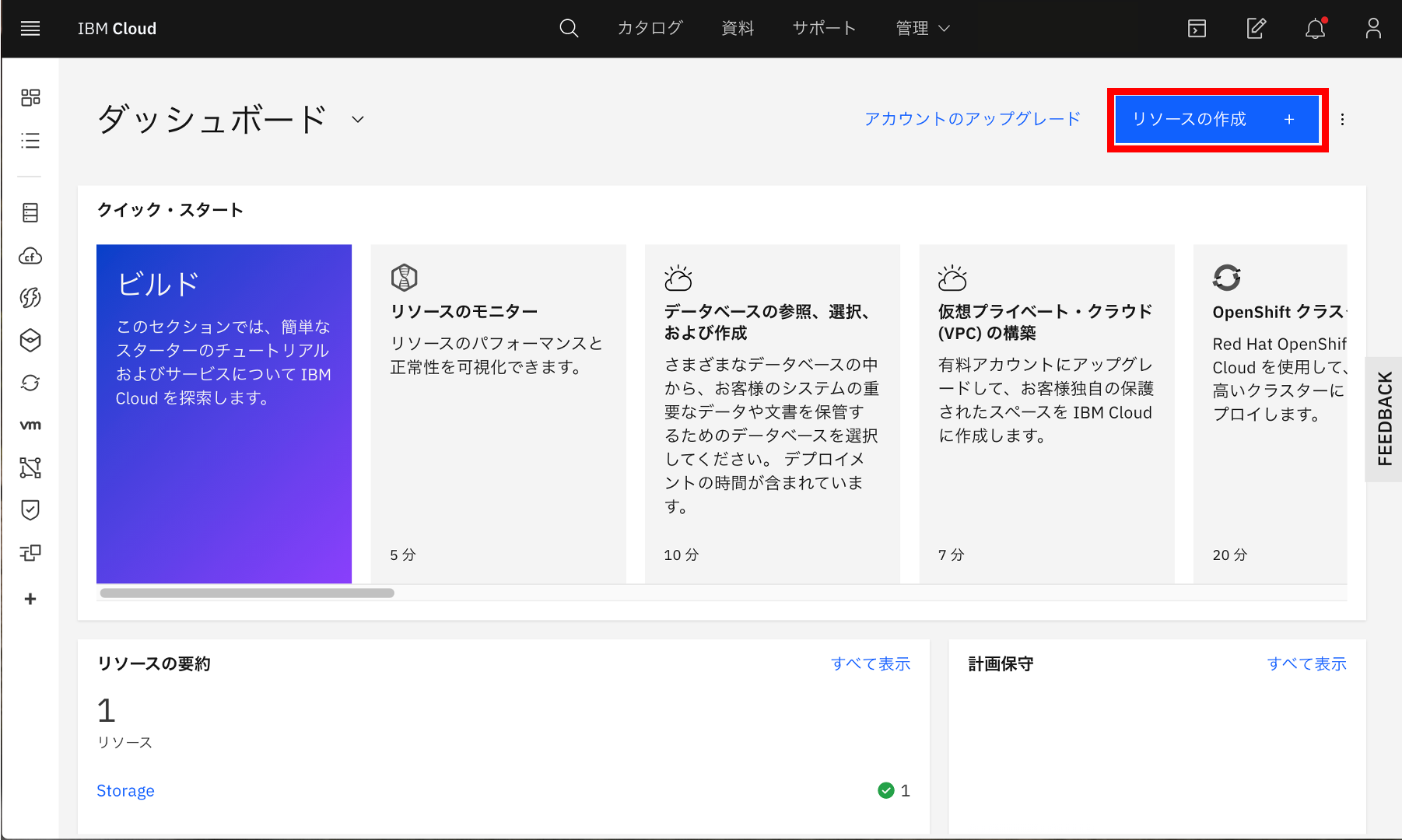
③Object Strageの選択
左側メニューから「フィーチャー」を選択し、その中にある「Object Strage」を選択します。
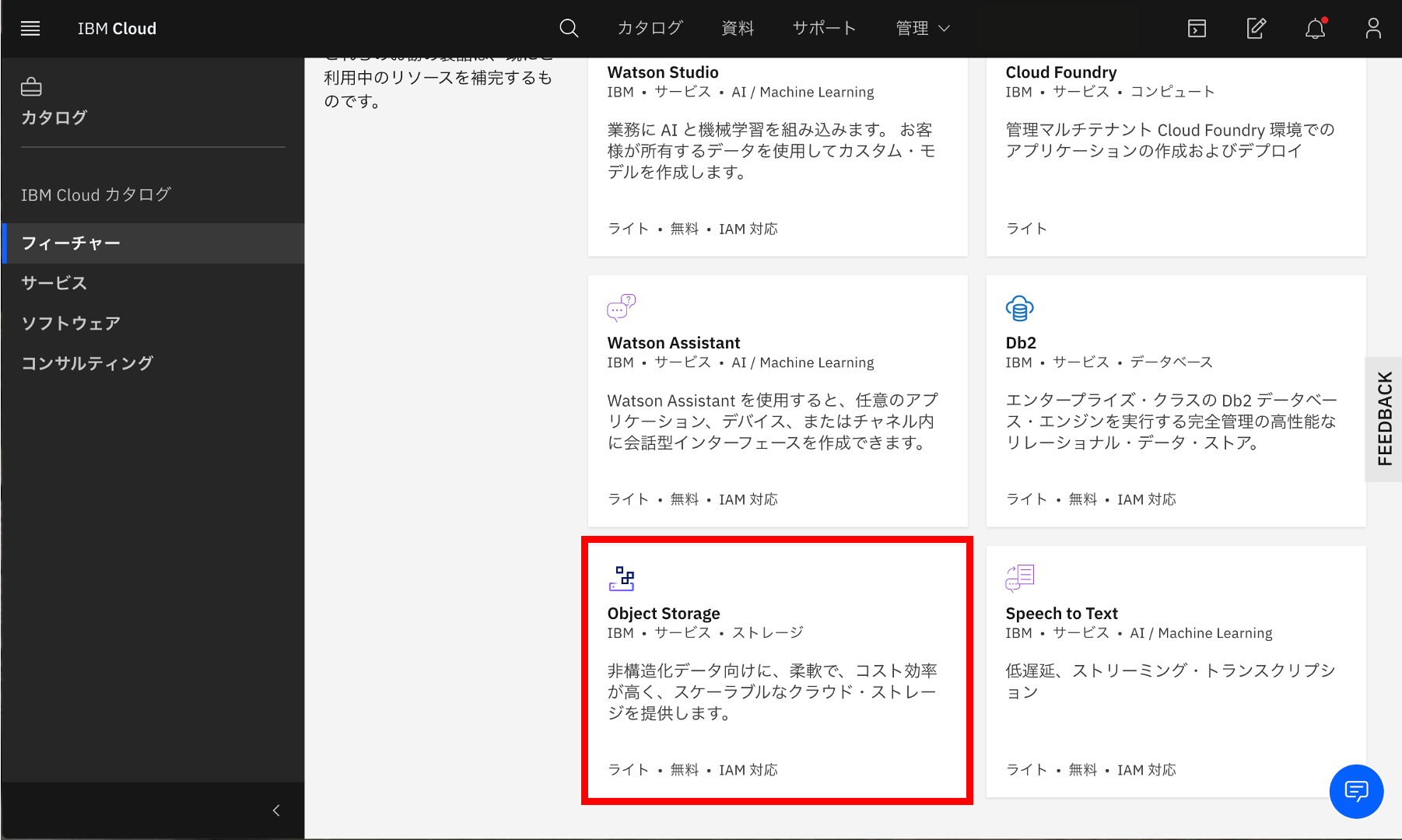
④Object Strageの設定
プランから「ライト(無料)」を選択し、ServiceNameを入力して「Create」ボタンをクリックします。
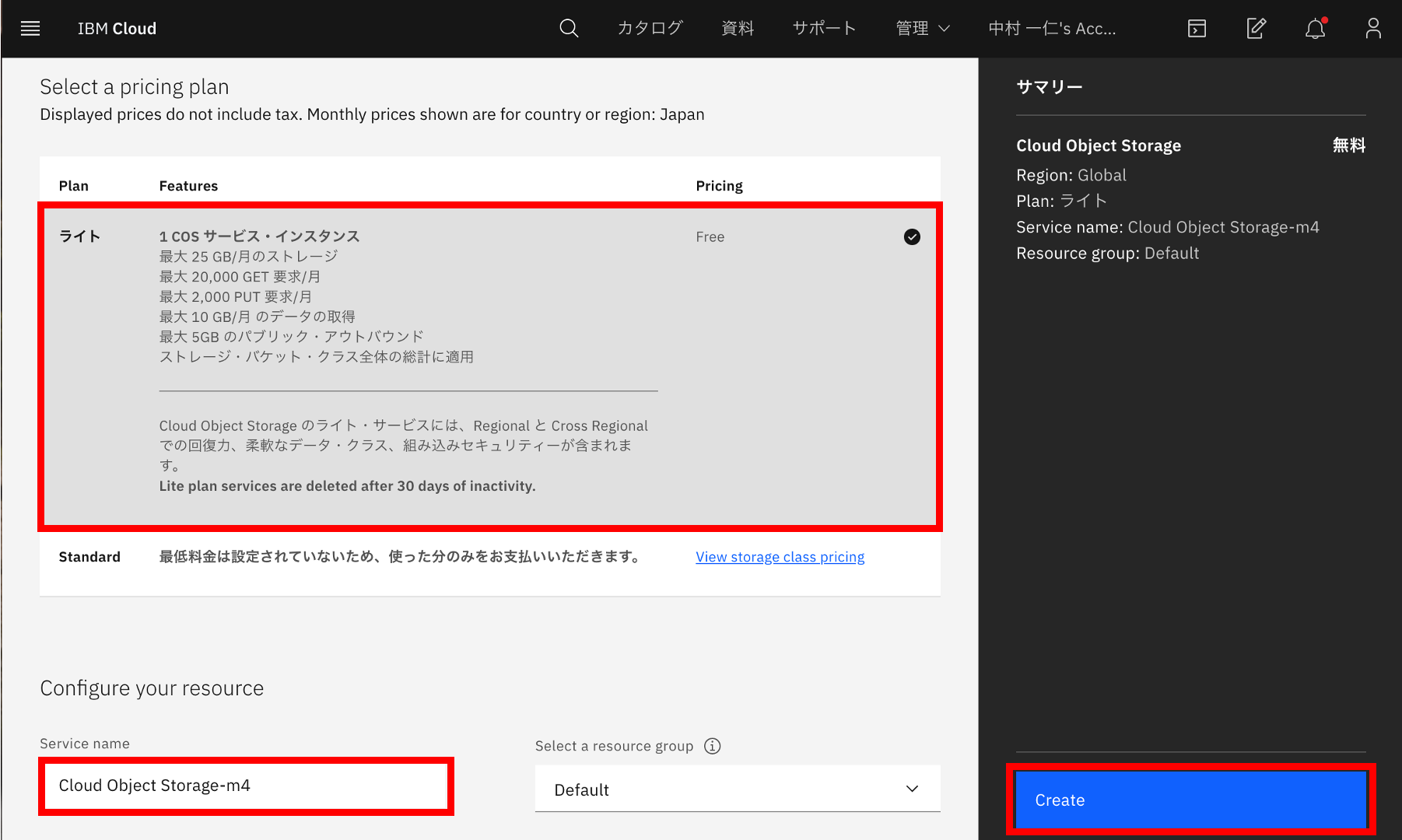
これで、ObjectStrageの作成は完了です。
アノテーションの実施
それでは、今回の本題のアノテーションをしていきましょう。
①Cloud Annnotationsにアクセス
IBM Cloud Annnotaionsのサイト「https://cloud.annotations.ai/login」にアクセスして、ログインします。
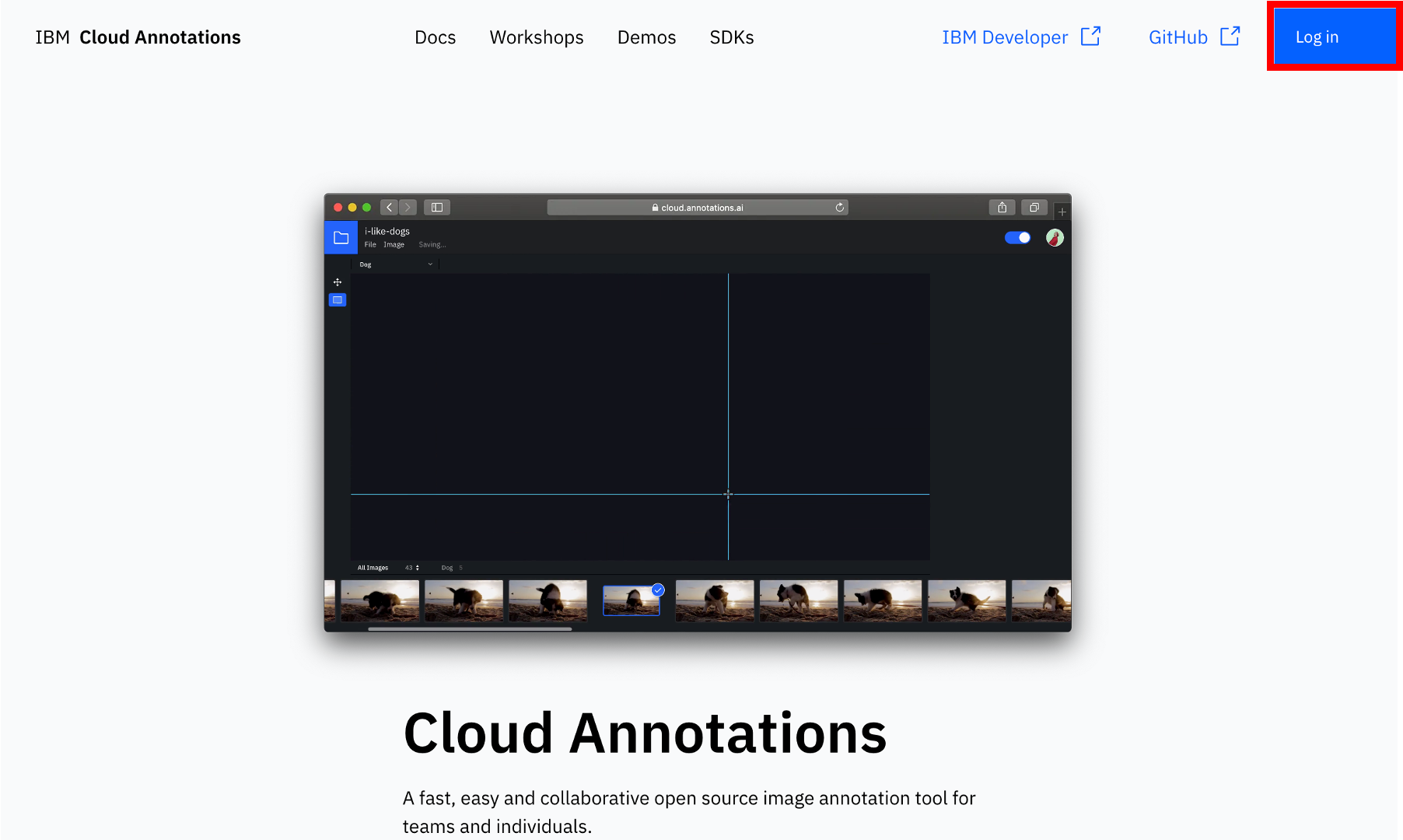
②プロジェクトの作成
画面右にある「Start a new project」ボタンをクリックします。
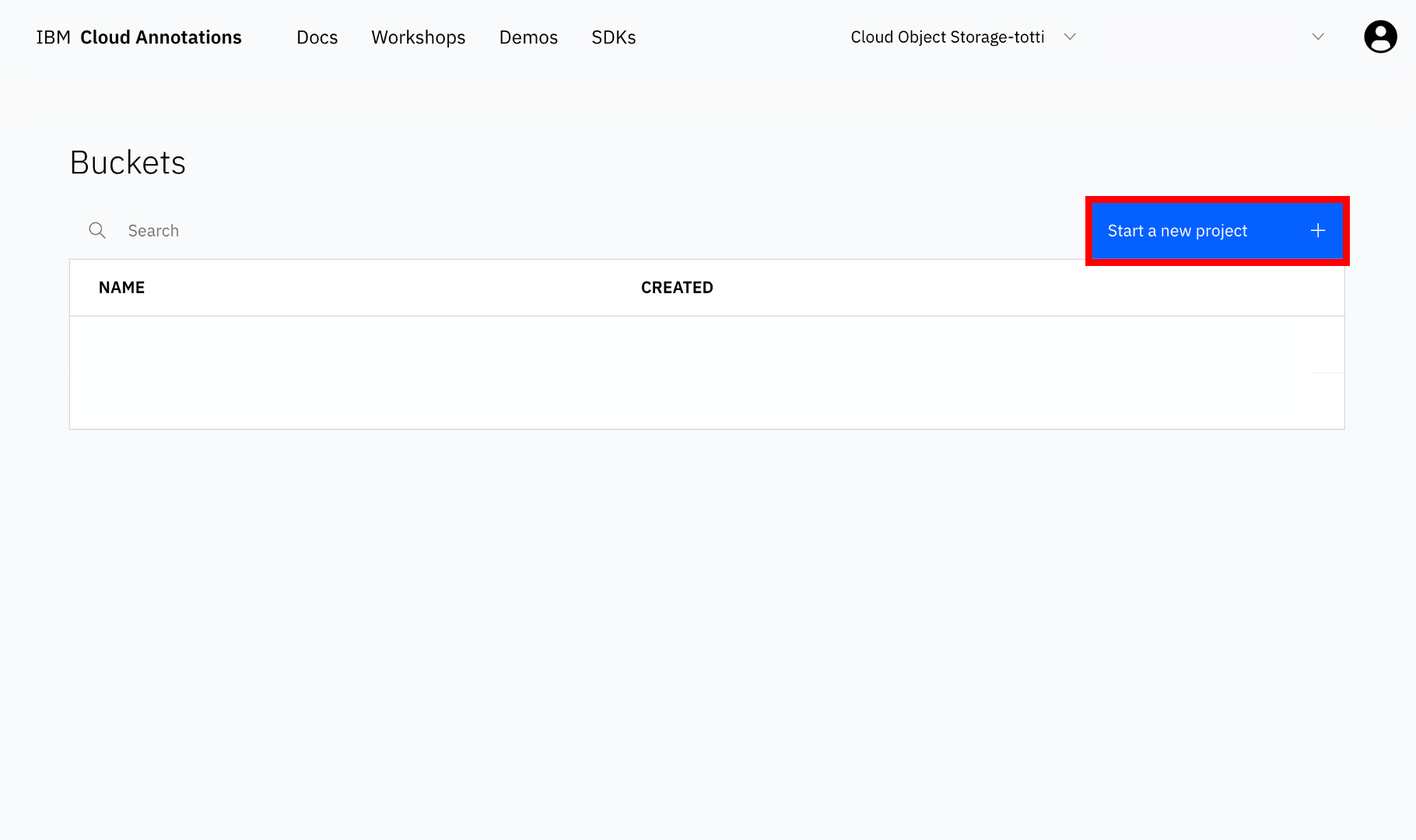
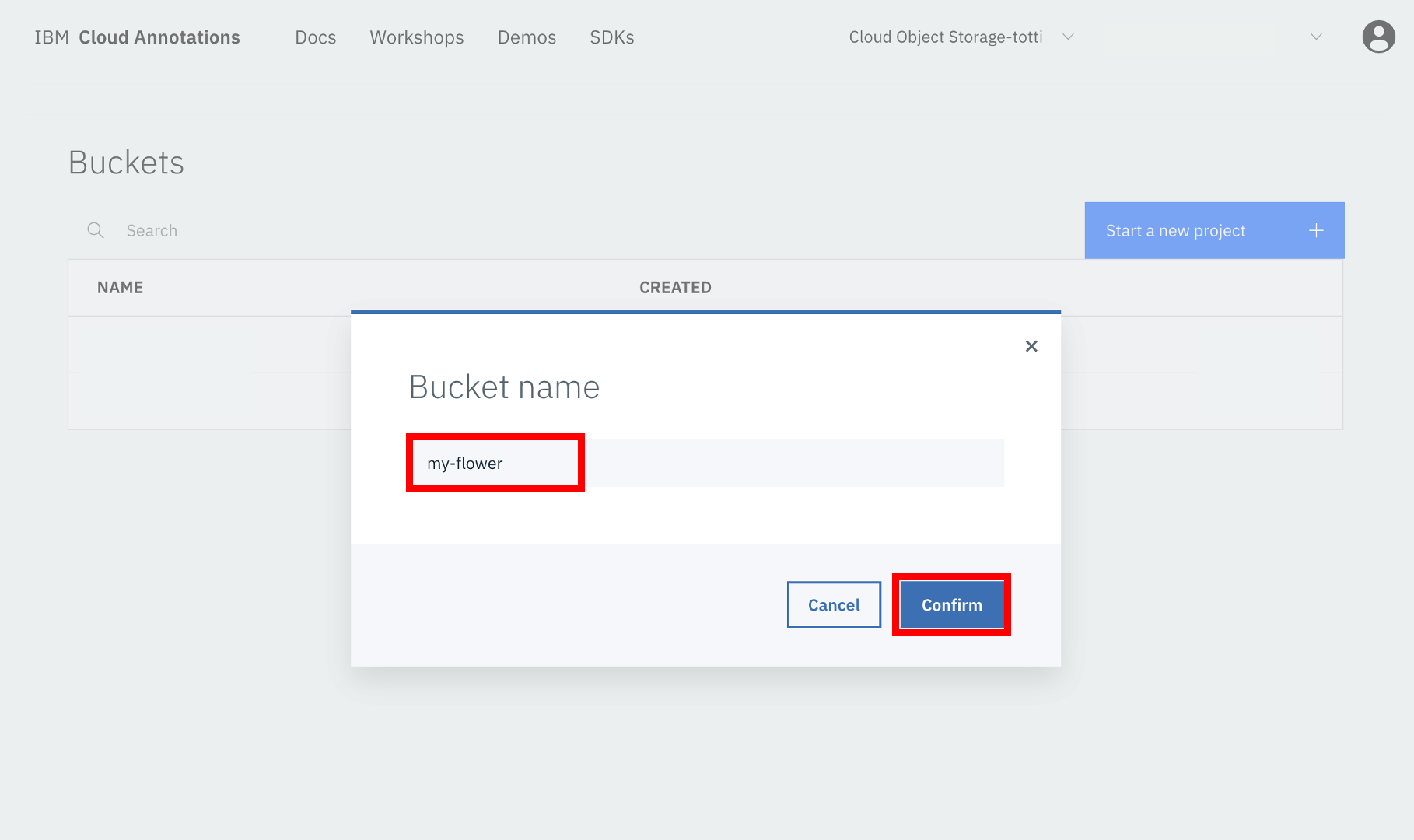
③バケツ名の設定
プロジェクトの名前(Bucket name)の入力を求められるので、適当に入力して「Confirm」ボタンを押します。アノテーションした結果を入れるものをバケツ(Bucket)というようです😄
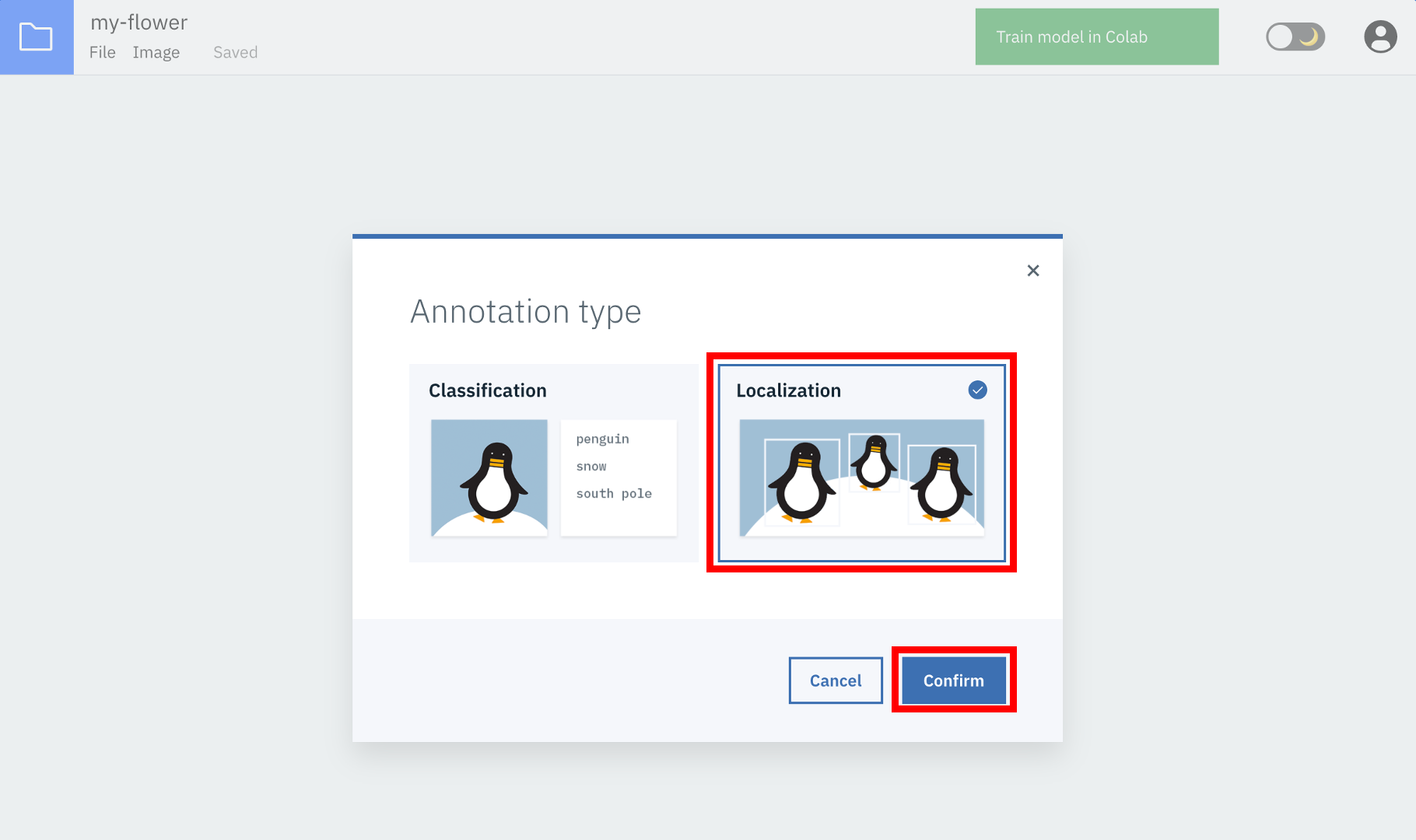
④タイプの選択
タイプの選択画面が表示されるので右側の「Localization」を選択して「Confirm」ボタンをクリックします。
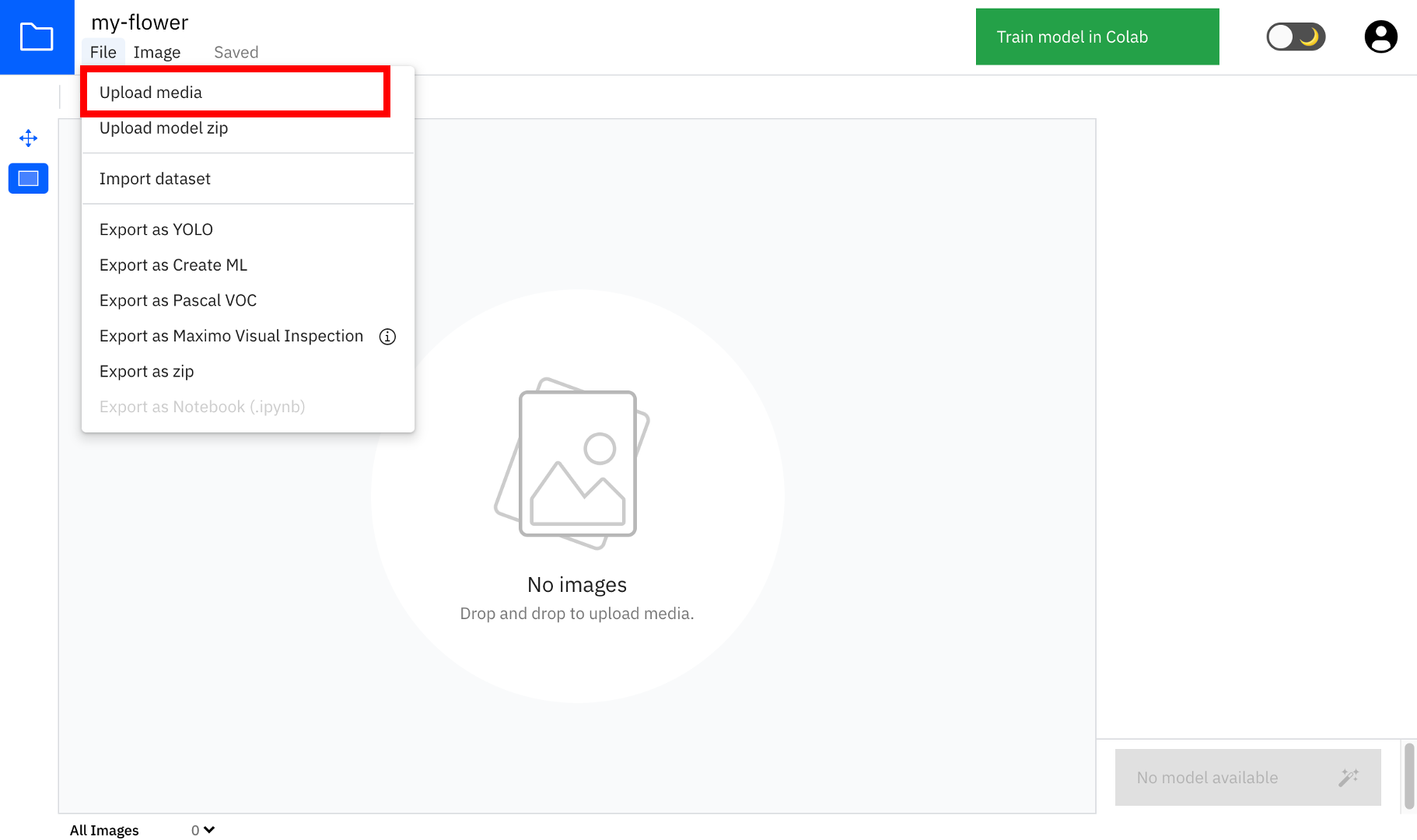
⑤検出物体動画のアップロード
画面左上の「File」から「Upload media」を選択し、上で撮影&変換した動画ファイルを選択します。
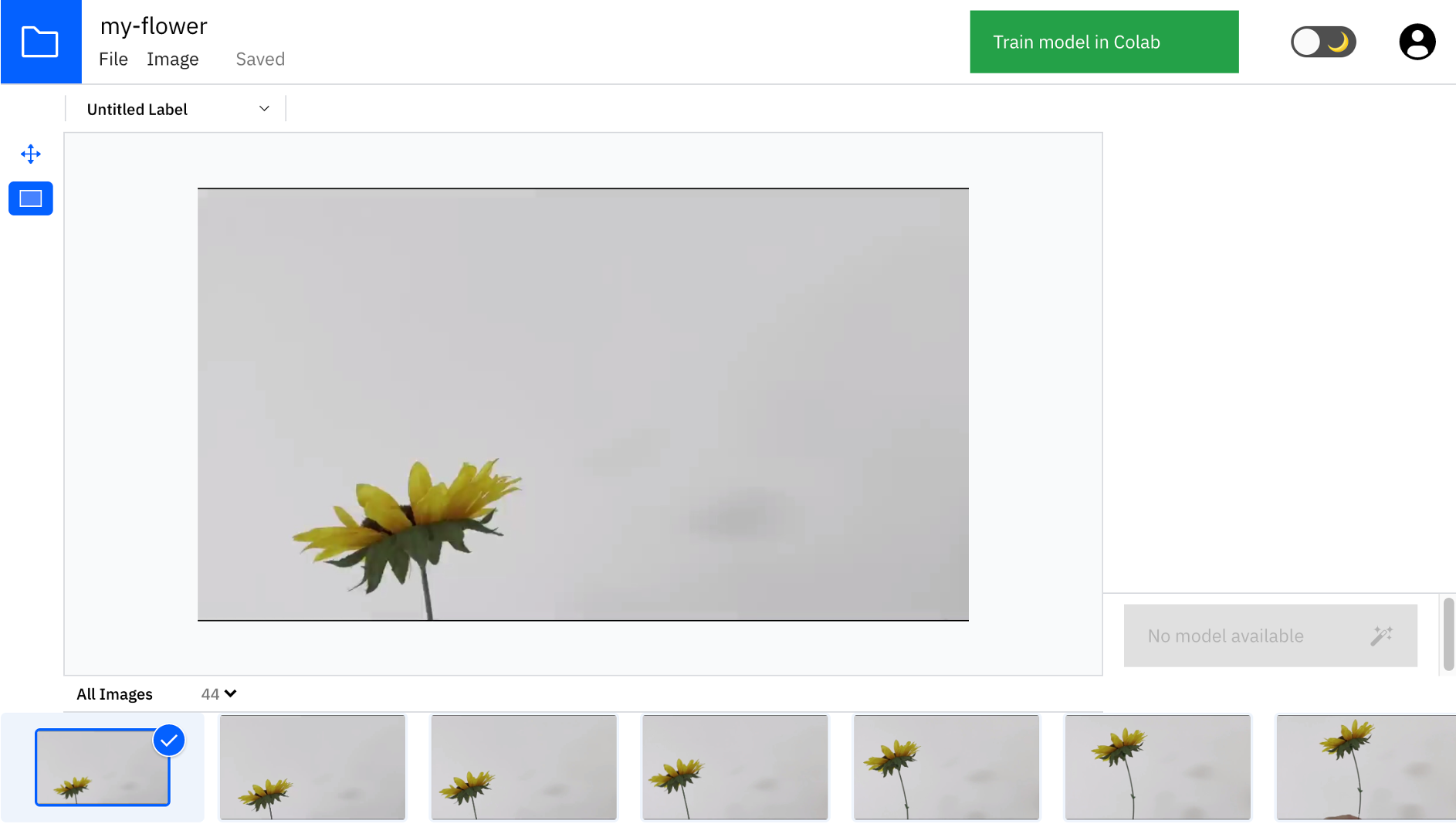
動画をアップロードして30秒ぐらい待つと、以下のように動画が解析され、動画内の画像が画面の下に表示されます。
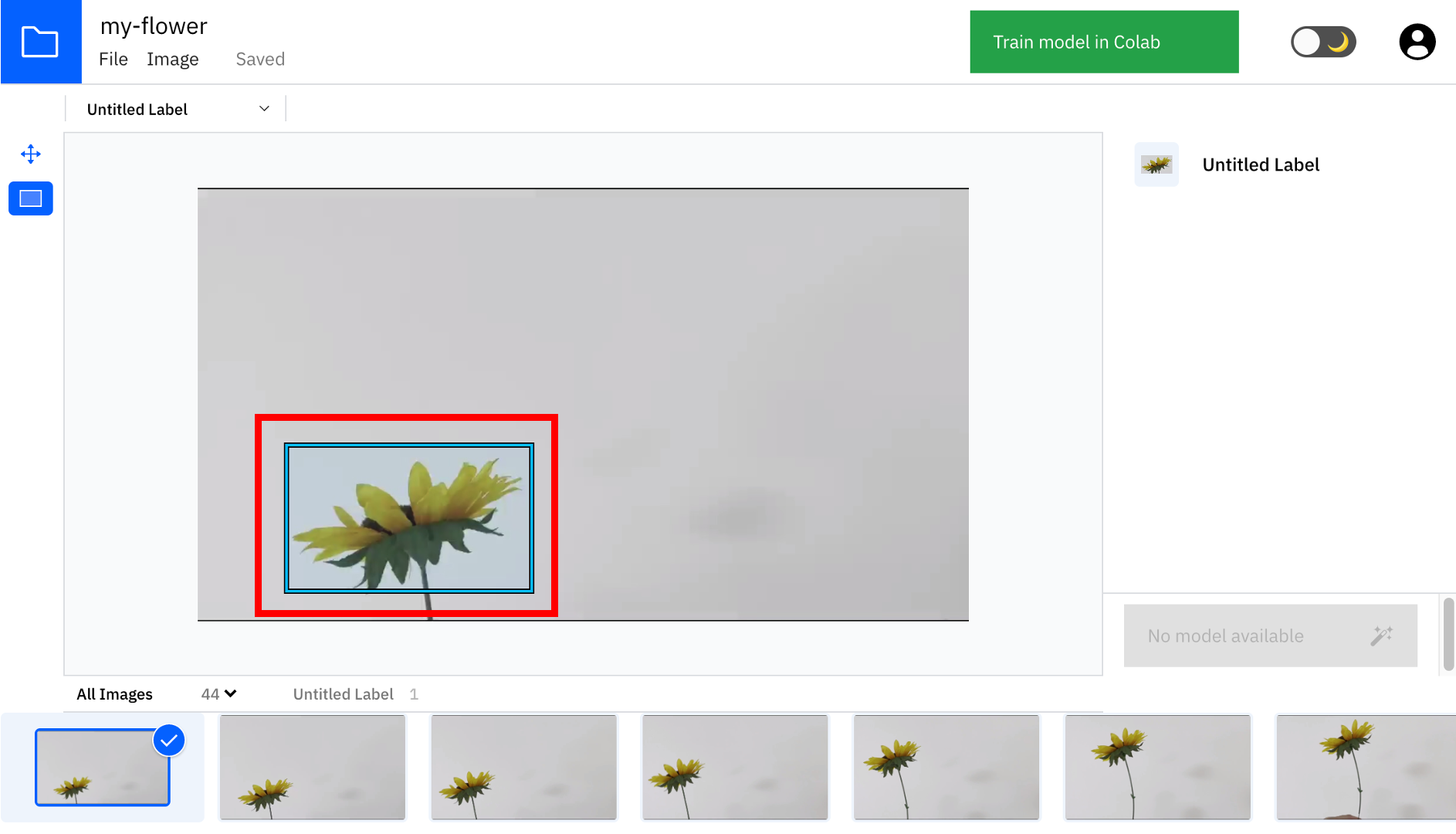
⑥アノテーションの実施
まずは1つの画像について、下図のようにマウスでドラッグして対象の物体の範囲を四角で囲います。
⑦ラベル名の入力
次に、画面右の「Untitled Label」の欄にある鉛筆マークをクリックして、ラベル名を入力します。
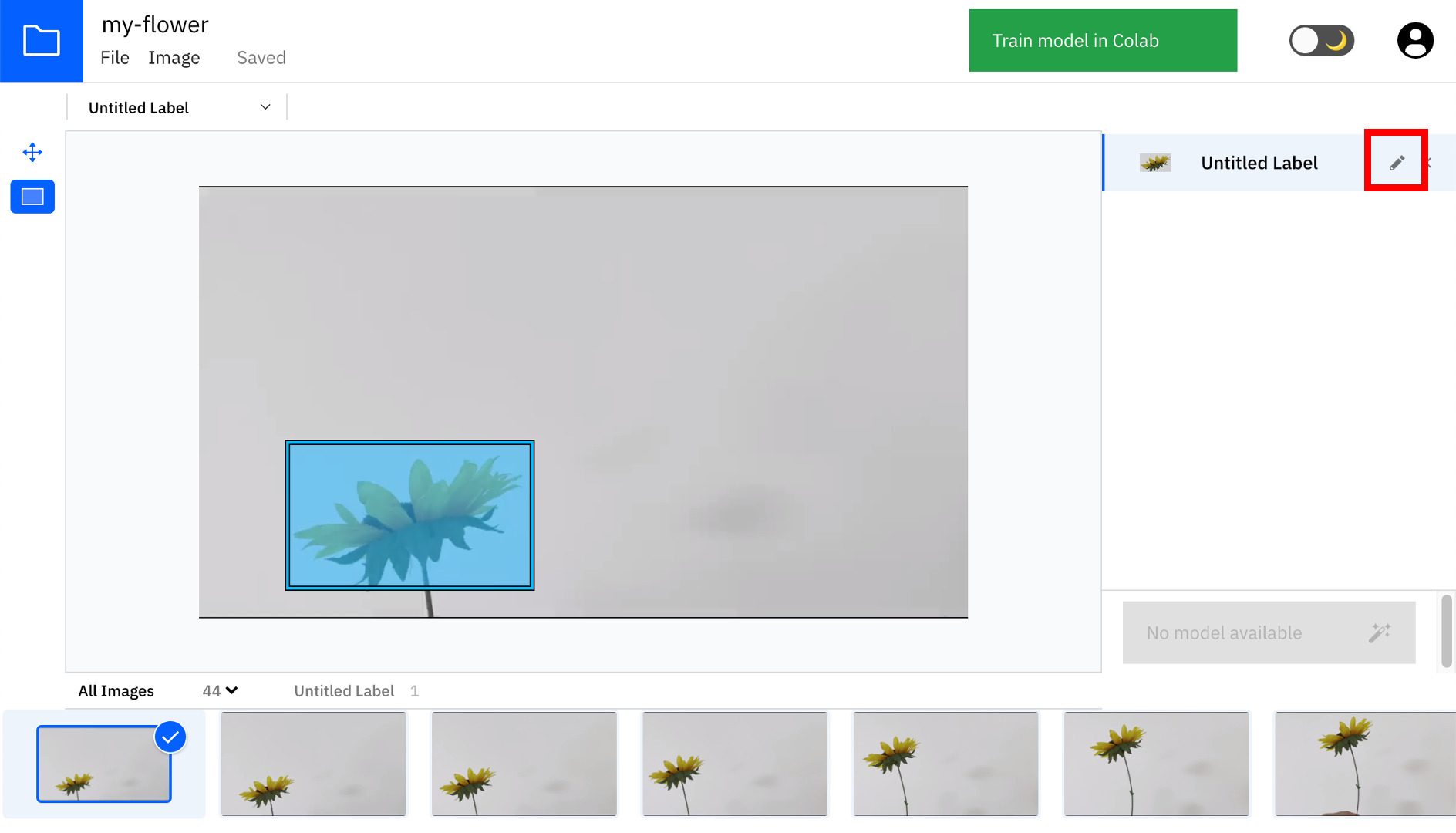
ラベル名を変更すると、以下のようになります。
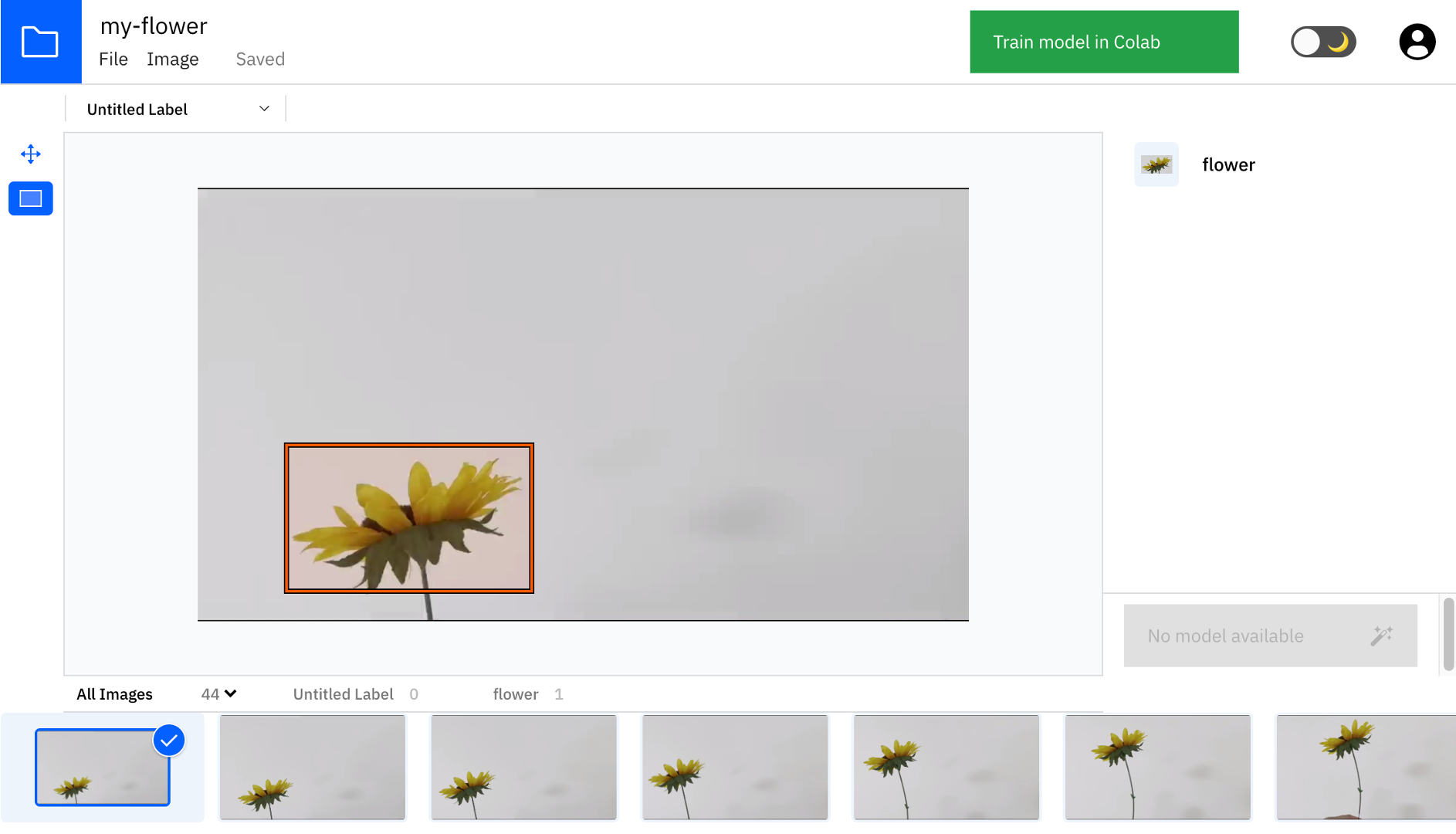
⑧ラベルの選択
次に、画面左上から入力したラベルを選択しておきます。
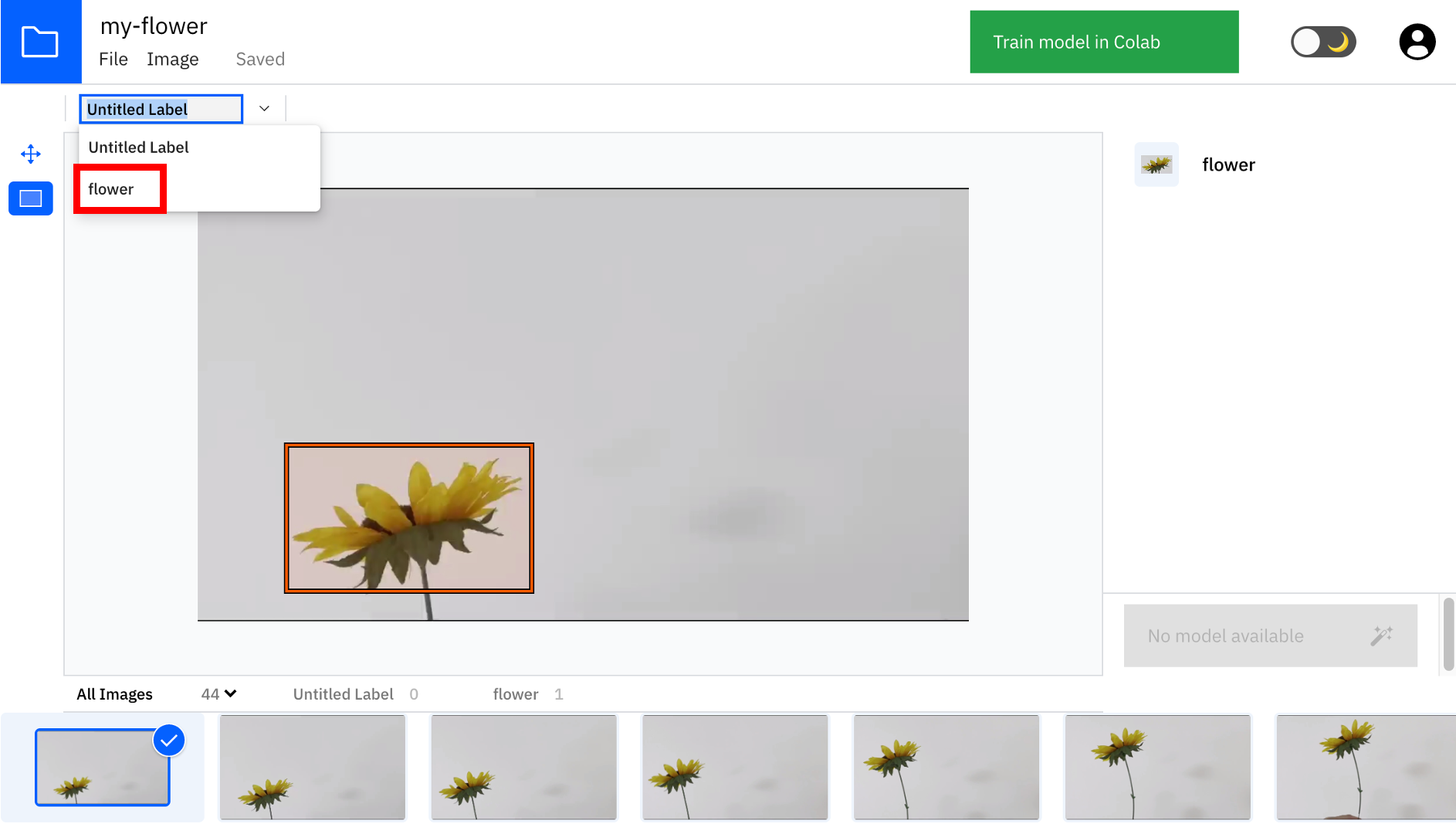
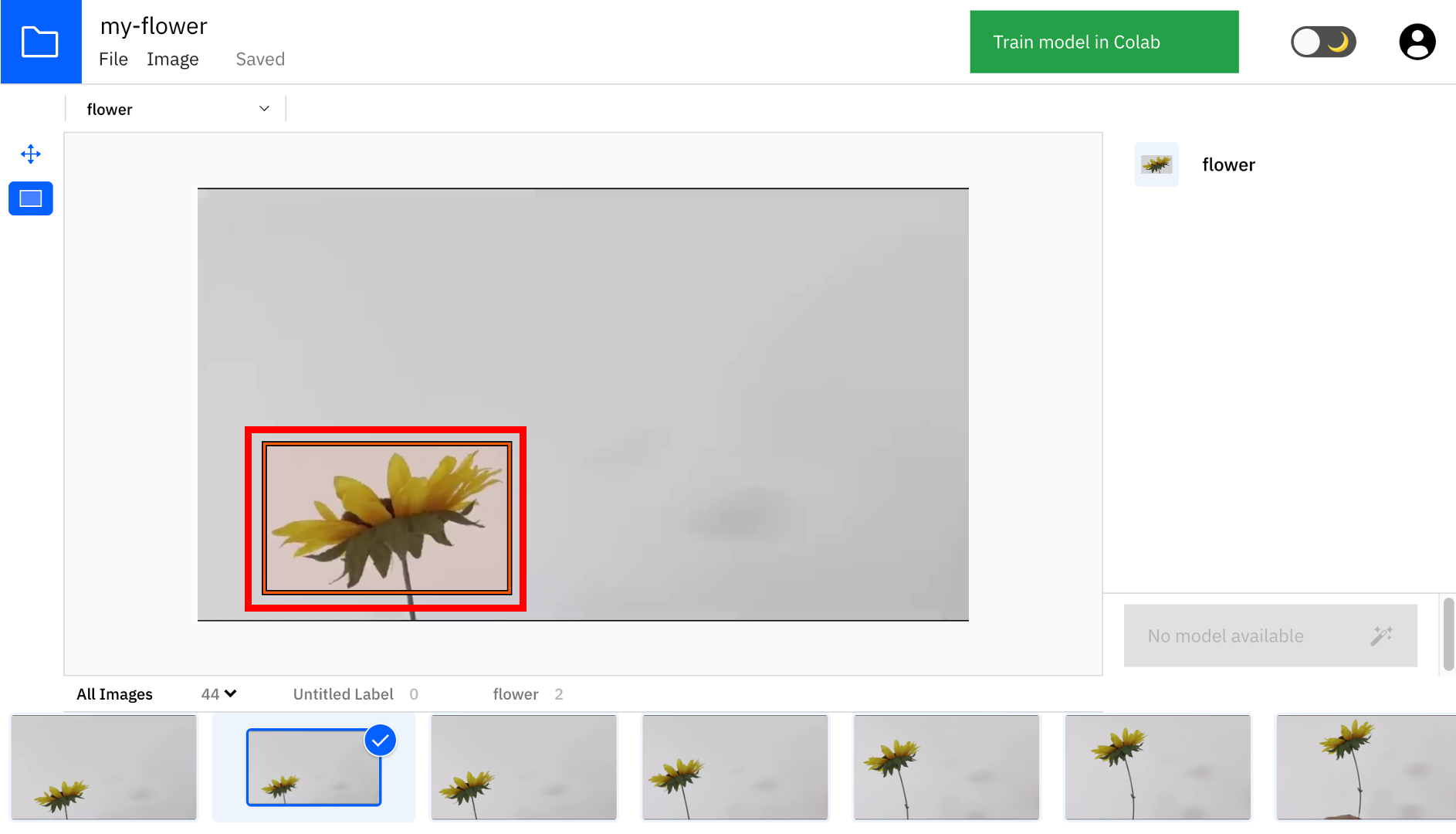
⑨ひたすらアノテーション
ここまで出来たら、画面下の沢山並んでいる画像に対して、ひたすら物体を囲って(アノテーション)いきます。大体、50〜100枚ぐらいはやった方が良いです。また、全ての画像に対して必ず選択する必要はありません。途中でやめてもOKです。
⑩アクセスキーなどの取得
十分な数のアノテーションが完了したら、画面右上の「Train model in Colab」をクリックします。すると以下の画像のようにaccess keyなどを含む接続文字列が表示されるので、これをテキストエディタなどにコピーしておきます。この文字列を使うことで、後でGoogle Colabから直接アノテーションしたデータにアクセス可能になります。
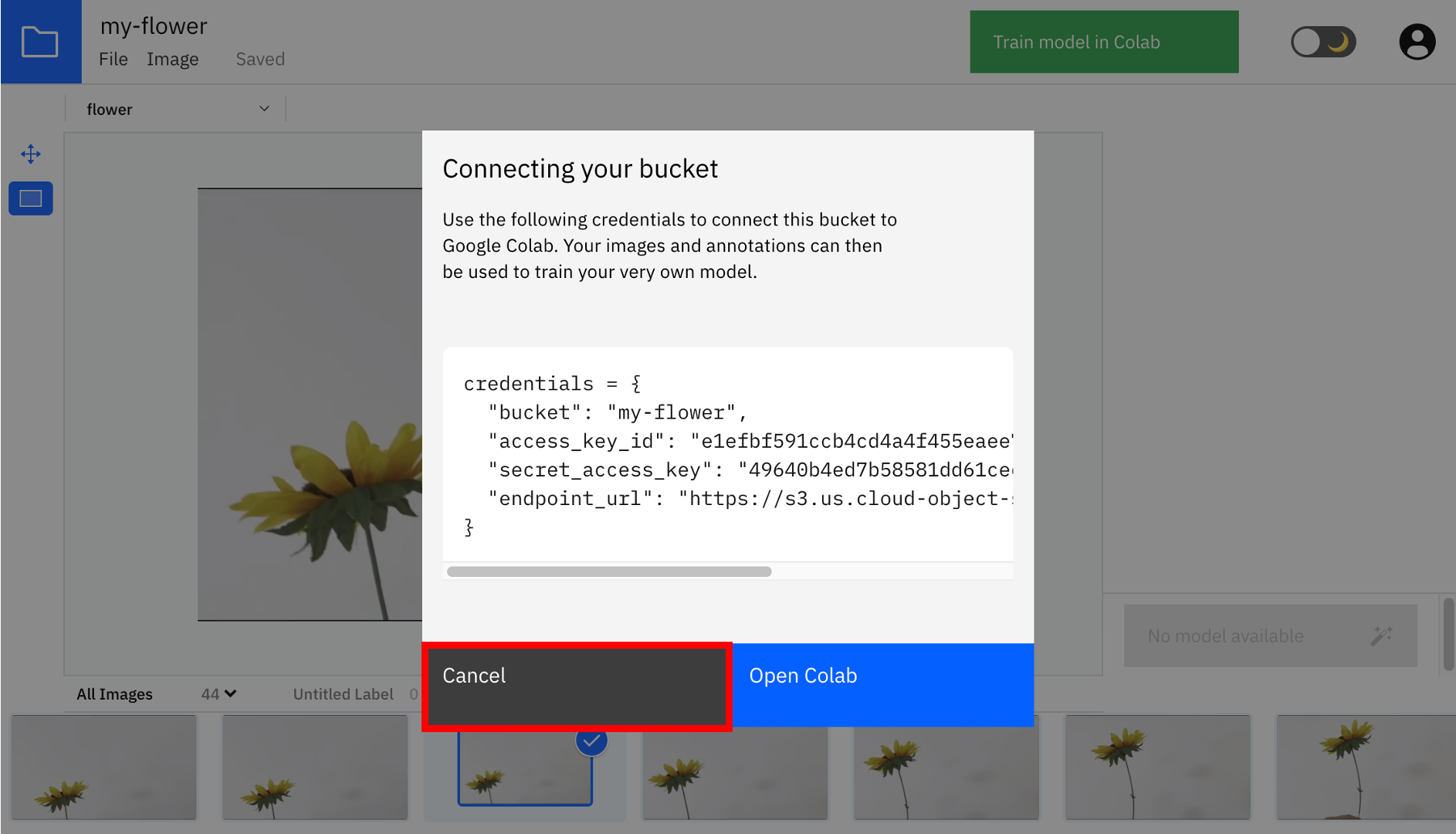
【参考】アノテーションデータの中身
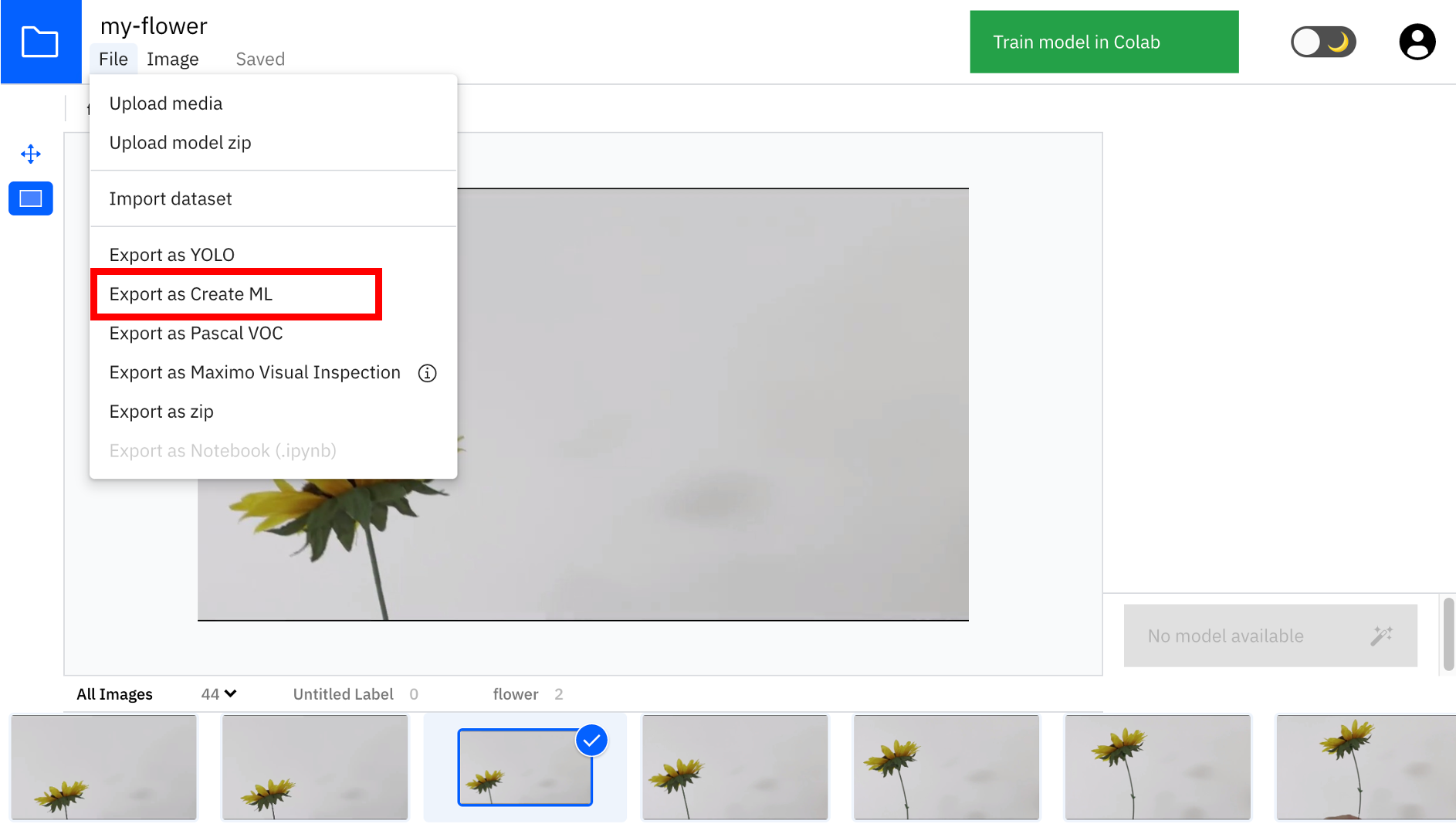
参考までに、アノテーションされたデータはどのような形式になっているかを確認してみましょう。画面左上の「File」から「Export as Create ML」をクリックします。すると、アノテーションデータがZipファイルでダウンロードできます。
ダウンロードしたZipファイルの中身は以下の通りです。複数の画像ファイルと、画像ファイル内の物体の範囲を示したannotaions.jsonファイルから構成されています。
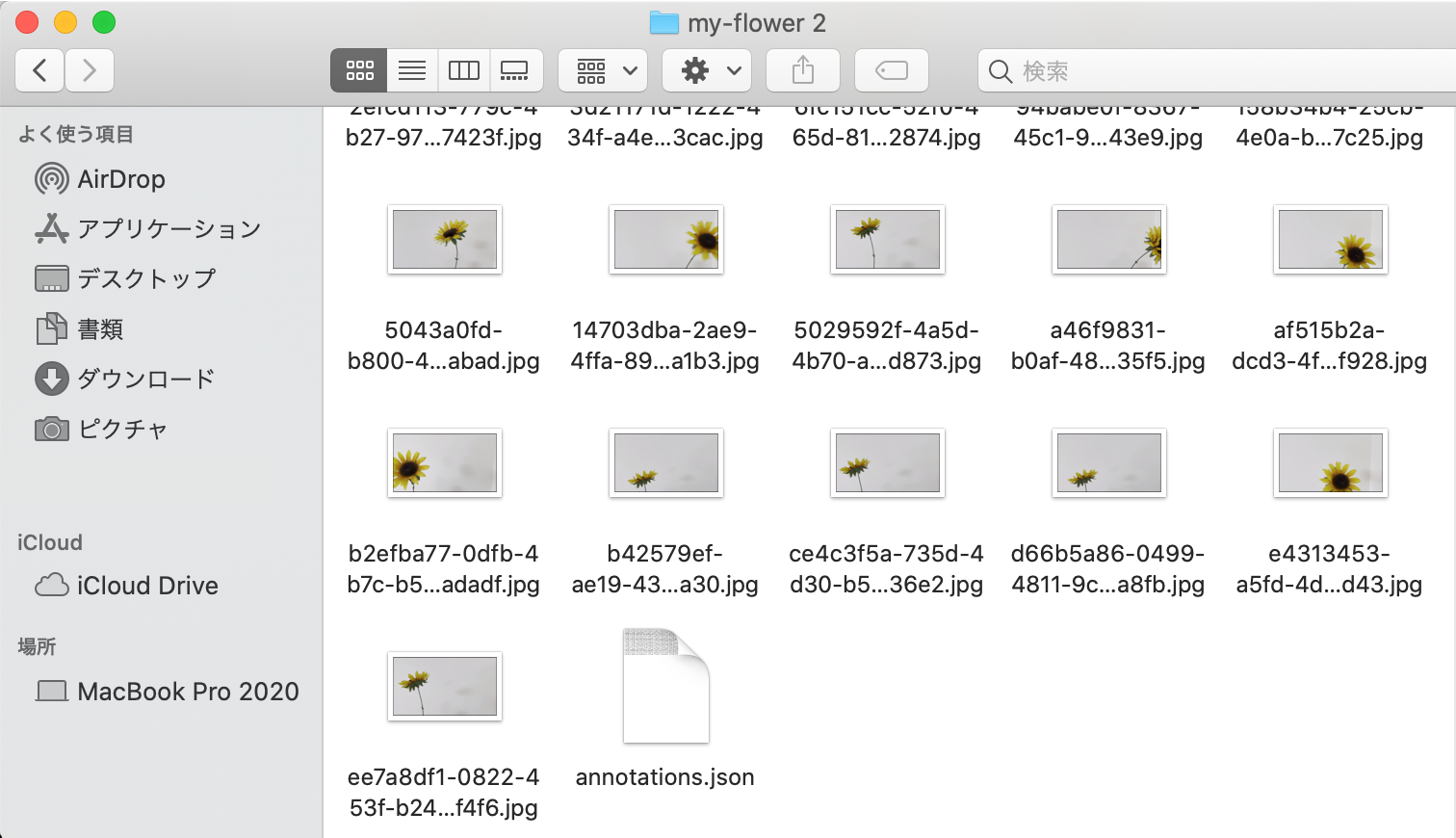
このデータが、物体検出用のモデルを作成する学習データとなります。
以上でアノテーションは完了です。
おわりに
今回は、Raspberry Piで物体検出を行う第1歩として、教師データの作成(アノテーション)を行なってみました。次回は、このデータを使ってGoogle Colabを使ってTensorflowの学習モデルを作成して行きたいと思います。
第1回:IBM Cloud Annotationsを用いたアノテーション
第2回:Google Colabを用いたモデルの学習 ←次回
第3回:Raspberry Piの環境構築
第4回:オリジナルモデルを用いた物体検出
関連記事






コメント